

چرا باید در این کارگاه شرکت کنیم؟
تقاضا برای توسعه دهندگان یادگیری عمیق و یادگیری تقویتی بسیار زیاد است و با توجه به نو بودن این زمینه و نیروی متخصص بسیار کم، این دوره میتواند فرصتی بینظیر برای رشد حرفه ای شما باشد. شما با استفاده از پایتون و کتابخانه های یادگیری عمیق، چندین الگوریتم یادگیری تقویتی عمیق را اجرا میکنید که به عنوان نمونه کار میتوانند بیانگر مهارت شما باشند. علاقه مندی به این حوزه و سرمایه گذاری در آن رو به افزایش است، با سرمایه گذاری زودهنگام میتوانید شما پیشرو این صنعت باشید.
سطح این رویداد در چه حدی می باشد؟
رویداد در سطح متوسط برگزار خواهد شد و مناسب افرادی است که درک اولیه از یادگیری ماشین و داده کاوی داشته باشند.
سرفصل های اصلی دوره شامل چه مواردی است؟
یادگیری تقویتی قابلیت یادگیری در محیط با اطلاعات پویا بر اساس پاداش/جزا را دارد. این نوع یادگیری در ترکیب با یادگیری عمیق میتواند مورد در موارد بسیار زیادی مورد استفاده قرار بگیرد. برای مثال سیستم ربات هوشمندی که میتواند بدون یادگیری اولیه، با توجه به پاداش/جزا در محیطی ناشناخته قدم گذاشته و به صورت هوشمند، وظایف مورد انتظار را انجام دهد. در این وبینار در مورد روشهای مختلف یادگیری تقویتی و یادگیری عمیق و ترکیب این دو صحبت خواهیم کرد و با استفاده از زبان برنامهنویسی پایتون مثالهایی از این مورد را خواهیم دید.
- یادگیری تقویتی چیست؟
- یادگیری عمیق چیست؟
- یادگیری تقویتی عمیق
- الگوریتمهای ارائه شده و نقاط قوت و ضعف هر کدام
- پیاده سازی مثال موردی کاربرد یادگیری عمیقی تقویتی در صنعت
آیا در پایان رویداد مدرک پایان دوره به شرکت کنندگان اعطا می شود؟
بله، مدرسه علم داده دارای مجوز شرکت خلاق از معاونت علمی و فناوری ریاست جمهوری، دارای مجوز واحد فناور از مرکز رشد پارک علم و فناوری تحت نظارت وزارت علوم تحقیقات و فناوری و دارای مجوز واحد فرهنگی دیجیتال از وزارت فرهنگ و ارشاد اسلامی است است، گواهینامه معتبر پایان دوره برای شرکت کنندگان صادر می گردد.
نمونه گواهینامه رسمی و معتبر مدرسه علم داده

توجه: گواهینامه مدرسه علم داده بدون کداختصاصی قابل استعلام و واترمارک درج شده در ذیل نام و نام خانوادگی، نام دوره و هم چنین امضای مدیریت فاقد اعتبار است.
آشنایی با مدرس رویداد

مسعود کاویانی
مهندس ارشد زیرساخت فناوری ابری پارسپک
دانشمند ارشد داده در صباایده (فیلیمو، آپارات، سینماتیکت)
آشنایی با موضوع اصلی رویداد
یادگیری تقویتی عمیق
Deep Reinforcement Learning
یادگیری تقویتی و یا یادگیری تقویتی عمیق یکی از زیرشاخه های یادگیری ماشینی است. یادگیری ماشینی، یکی از علوم نوظهوری است که در سالهای اخیر از رشد بسیار بالایی برخوردار بوده است، به طوری که تخمین زده شده است که در حال حاضر دارای بازار 7.3 میلیارد دلاری است که روز به روز نیز بر مقدار آن افزوده میشود. موسسه مکنزی پیشبینی کرده است که تکنیکهای هوش مصنوعی مانند یادگیری عمیق و یادگیری تقویتی دارای پتانسیل ایجاد درآمد سالیانه در حدود 5.8 تریلیون دلار هستند و میتوانند در بیش از 18 صنعت به صورت تجاری پیادهسازی شوند
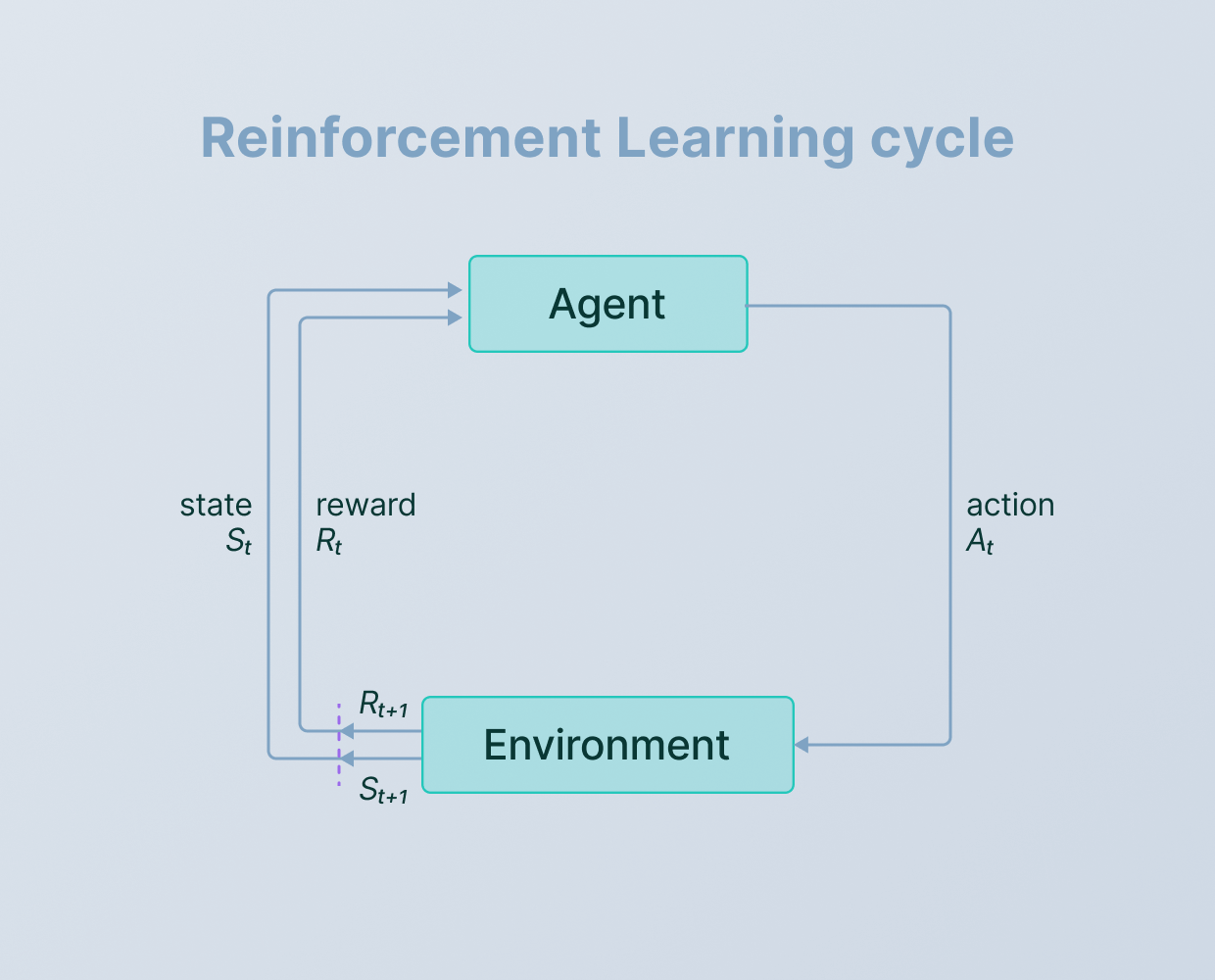
معرفی یادگیری تقویتی
یادگیری تقویتی فرآیند نگاشت موقعیتها به اقداماتی است که در نهایت منجر به حداکثر نمودن پاداش دریافتی میشود. بنابراین عامل یادگیرنده با انتخاب اقدامات و مشاهده نتایج آنها، سعی در حداکثر نمودن پاداش دریافتی مینماید. نکته قابل توجه اين است که اين اقدامات نه تنها پاداش دريافتي آني را تحت تاثير قرار ميدهد، بلکه تمامي پاداشهاي بعدي را نيز متاثر ميسازد. اين دو خصوصيت سعي و خطا و پاداش با تاخير مهمترين وجه تمايز روش يادگيري تقويتي با ساير روشها است.
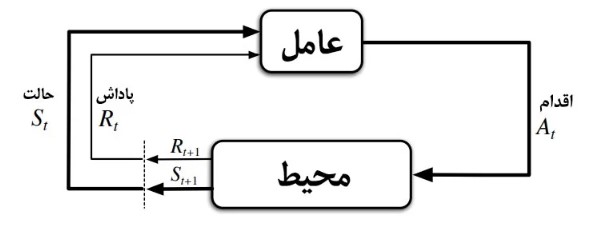
همانطور که در شکل بالا نشان داده شده است، عامل در ابتدا اقدامی را در محیط اتخاذ میکند، سپس محیط تاثیر آن اقدام را در قالب پاداش و حالت بعدی سیستم به عامل برمیگرداند. این فرآیند تا آنجا ادامه پیدا میکند که سیاست بهینه استخراج شود. بنابراین سلسله اتفاقات در این سیستم به صورت زیر خواهد بود:
![]()
یادگیری تقویتی بر خلاف دو روش قبلی یادگیری ماشینی (یادگیری با نظارت و بدون نظارت) داده ورودی دریافت نمینماید. در این روش یک محیط در اختیار عامل یادگیرنده قرار میگیرد. عامل یادگیرنده با انجام اقدامات مختلف و دریافت پاداش حاصل از اقدامات، به سمت سیاست بهینه حرکت مینماید.
اجزاء یادگیری تقویتی
یادگیری تقویتی دارای عناصر اصلی زیر است که در توسعه هر الگوریتم میبایست به درستی تعریف شوند:
عامل (Agent): عامل در یادگیری تقویتی وظیفه یادگیری و استخراج سیاست بهینه را بر عهده دارد. عامل با محیط در تعامل است و اقدامات را اتخاذ میکند.
محیط (Environment): محیطی است که عامل در تعامل با آن و اتخاذ تصمیمات مختلف حالات را تغییر میدهد. محیط پس از اقدام عامل تغییر میکند و بازخورد آن را به عامل برمیگرداند.
اقدام (Action): حرکتی است که عامل پس از مشاهده وضعیت سیستم انتخاب میکند.
حالت (State): وضعیتی که محیط در حال حاضر در آن قرار دارد و عامل با مشاهده آن تصمیم به حرکت بعدی میگیرد.
پاداش (Reward): عامل پس از مشاهده حالت سیستم و انتخاب اقدام، پاداش مشخص آن اقدام را دریافت میکند. پاداش به عنوان سیگنال بازخورد اقدام تعریف میشود که عامل را به سمت سیاست بهینه هدایت میکند.
سیاست (Policy): نحوه رفتار عامل به عنوان سیاست شناخته میشود. بنابراین عامل بسته به سیاست در نظر گرفته شده، بعد از مشاهده حالت سیستم اقدام مشخصی را انتخاب میکند.
تابع ارزش (Value function): همانطور که ذکر شد “پاداش” بازخورد آنی از اقدام عامل است. ولی اگر بخواهیم بلندمدت نگاه کنیم، به این معنی که این اقدام عامل در بلند مدت چه تاثیری خواهد داشت، از آن به عنوان تابع ارزش نام برده میشود. بنابراین تابع ارزش، بازخورد بلندمدتی است که عامل با استفاده از سیاست مشخص و اقدام اتخاذ کرده در حالت مشخص سیستم دریافت میکند.
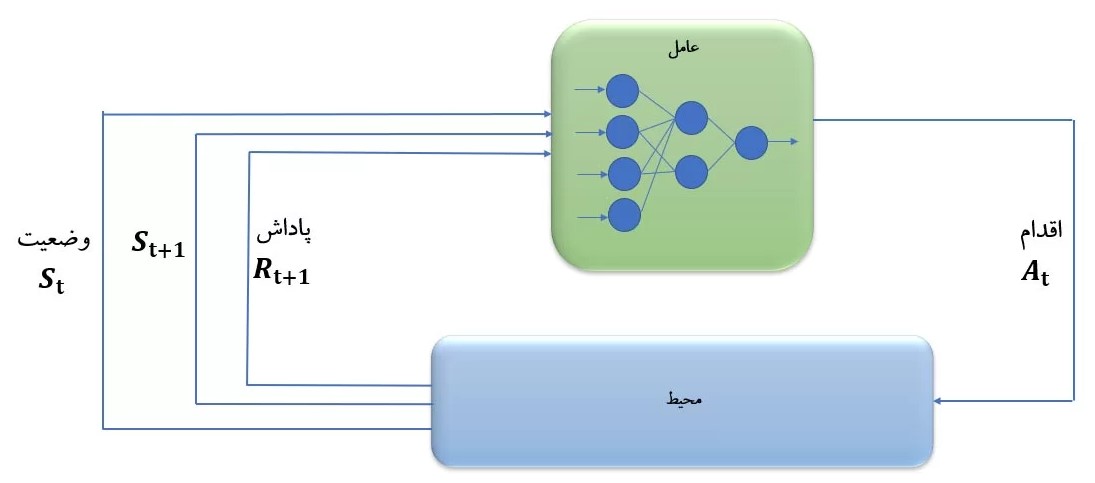
یادگیری تقویتی عمیق (Deep Reinforcement Learning)
همانطور که ذکر شد، عامل یادگیرنده در فرآیند یادگیری تقویتی نیاز دارد تا تابع ارزش را محاسبه و ذخیر نماید. اما در مواقعی که ابعاد مساله بزرگ باشد، ذخیره تمامی ارزشهای حالتهای مختلف سیستم عملاً غیرممکن خواهد بود. در اینگونه مواقع به سراغ روشهای تخمین تابع ارزش (Approximate value function) خواهیم رفت. روشهای تقریب مختلفی وجود دارد که برخی از آنها عبارتند از:
- تقریب زننده خطی (Linear Approximator)
- تقریب زننده غیرخطی (Non-linear approximator)
- شبکه عصبی (Neural Network)
- نزدیکترین همسایه (Nearest neighbor)
- و …
در صورتی که در روش یادگیری تقویتی، برای تخمین تابع ارزش از شبکه عصبی استفاده شود، شاخه جدیدی به نام یادگیری تقویتی عمیق (Deep Reinforcement Learning) شکل میگیرد که در سالهای اخیر کاربردهای یادگیری تقویتی در طیف وسیعی از حوزه ها آزمایش شده است. یادگیری تقویتی عمیق موضوعی بسیار جذاب جهت انجام پروژه های تحقیقاتی و کاربردی است. عملکرد یادگیری تقویتی عمیق در سال 2015 در انجام بازیهای کامپیوتری نشان داده شد و بعد از آن الگوریتم های متعددی جهت بهتر شدن کارایی آن پیشنهاد شد.
دانلود فیلم ضبط شده رویداد
دانلود فیلم ضبط شده رویداد ویدئو
2:55:47
دوره های مرتبط

دوره آموزشی تحلیل شبکه های اجتماعی و پیچیده با پایتون

کارگاه آموزشی پروژه محور بررسی Kubernetes Workloads و نحوهی استفاده از آنها

مینی دوره آموزشی بینایی ماشین و یادگیری عمیق

کارگاه آموزشی داده محور رمزنگاری

کارگاه آموزشی پروژه محور شبکه های مولد تخاصمی (GAN)

کارگاه آموزشی پروژه محور اصول پردازش زبان طبیعی در پایتون

کارگاه آموزشی متدلوژی توسعه پروژه های تحلیل داده

کارگاه آموزشی پروژه محور Docker برای علم داده

دوره جامع پروژه محور یادگیری عمیق با پای تورچ (PyTorch)
Deep Learning with PyTorch Framework

پلتفرم بعنوان سرویس با Docker برای مهندسان داده
امتیاز دانشجویان دوره
نظرات
تنها اشخاصی که این محصول را خریداری کرده اند و وارد سایت شده اند می توانند در مورد این محصول بازبینی ارسال کنند.
199,000 تومان

مسعود کاویانی
دانشمند ارشد علم دادهدانشمند ارشد داده در صباایده (آپارت، فیلیمو، صباویژن)، مهندس داده زیرساخت ذخیرهسازی ابری پارسپک
رها همایون فر( دانشجوی دوره )
برای من که تازه قرار هست با reinforcement learning آشنا بشم خوب بود
بهار( دانشجوی دوره )
چرا لینک برای گرفتن دوره های ثبت نام شده فعال نیست؟
محمد حیدری(مدیریت)
پس از تهیه دوره به پایین صفحه دوره اسکرول کنید. بخشی بنام “دانلود فیلم ضبط شده رویداد ویدئو” مشاهده می کنید.