

چرا باید در این کارگاه شرکت کنیم؟
Warehouse یا انبار داده مهمترین بخش یک سیستم تحلیل داده به شمار میرود. اما طراحی آن نیاز به دانش تجربی و نظری قدرتمندی دارد. همچنین ابزارهای بسیار متنوعی برای واکشی و استخراج دادهها از دیتابیسهای عملیاتی و انتقال آنها به انبار داده وجود دارد. در این کارگاه آموزشی پروژه محور قصد داریم تا با استفاده از Spark چند جدول از درون دیتای یک روز اکشنهای کاربران استخراج کنیم.
سطح این رویداد در چه حدی می باشد؟
رویداد در سطح پیشرفته برگزار خواهد شد و مناسب افرادی است که با Spark، Parquet, Database Design آشنایی داشته باشند.
سرفصل های اصلی دوره شامل چه مواردی است؟
- Warehousing. چرا و چگونه؟
- Parquet و دیگر تکنیکهای ذخیرهسازی داده
- طراحی یک Data Mart کوچک
آیا در پایان رویداد مدرک پایان دوره به شرکت کنندگان اعطا می شود؟
بله، مدرسه علم داده دارای مجوز شرکت خلاق از معاونت علمی و فناوری ریاست جمهوری، دارای مجوز واحد فناور از مرکز رشد پارک علم و فناوری تحت نظارت وزارت علوم تحقیقات و فناوری و دارای مجوز واحد فرهنگی دیجیتال از وزارت فرهنگ و ارشاد اسلامی است است، گواهینامه معتبر پایان دوره برای شرکت کنندگان صادر می گردد.
نمونه گواهینامه رسمی و معتبر مدرسه علم داده

توجه: گواهینامه مدرسه علم داده بدون کداختصاصی قابل استعلام و واترمارک درج شده در ذیل نام و نام خانوادگی، نام دوره و هم چنین امضای مدیریت فاقد اعتبار است.
آشنایی با مدرس رویداد

حمید جهانی
حمید، فارغ التحصیل ارشد Data Science از دانشگاه تربیت مدرس تهران است. حمید بعنوان Business Data Analyst در Digikala فعالیت داشته است و در حال حاضر Data Scientist در شرکت Snappfood است.
آشنایی با موضوع رویداد
امروزه تقریباً هر سازمانی به طور گسترده از دادههای کلان برای دستیابی به برتری رقابتی در بازار استفاده میکند و خلق راهکارهای جدید و ابزارهای قدرتمند جهت مدیریت داده های بزرگ کمک بسیار شایانی به متخصصین بیگ دیتا و مدیران سازمان ها در تحلیل هرچه بهتر داده ها و تصمیم گیری های درست خواهد کرد.
آپاچی اسپارک یک Engine بسیار قدرتمند، برای پردازش دادههای بزرگ به صورتِ توزیعشده است که قابلیت پردازش داده ها به صورت Parallel یا موازی روی چندین کامپیوتر به صورت خودکار و همزمان را داراست. مهم ترین نکته در فناوری Spark مدیریت داده ها به صورت Real Time می باشد و همچنین با پردازش داده ها در Ram سرعت پردازش را بالا برده و موجب افزایش قدرت محاسباتی می شود.
موتور Spark با ارائه API برای توسعه دهندگان وظیفه برنامه نویسی را از دوش آنها برداشته و کار آنها را بسیار آسان کرده است و نیازی نیست برای استفاده از سرویس های این سرور به صورت صفر تا صد کدنویسی انجام شود ، فقط کافی است تکنیک های استفاده از API را بلد باشیم.
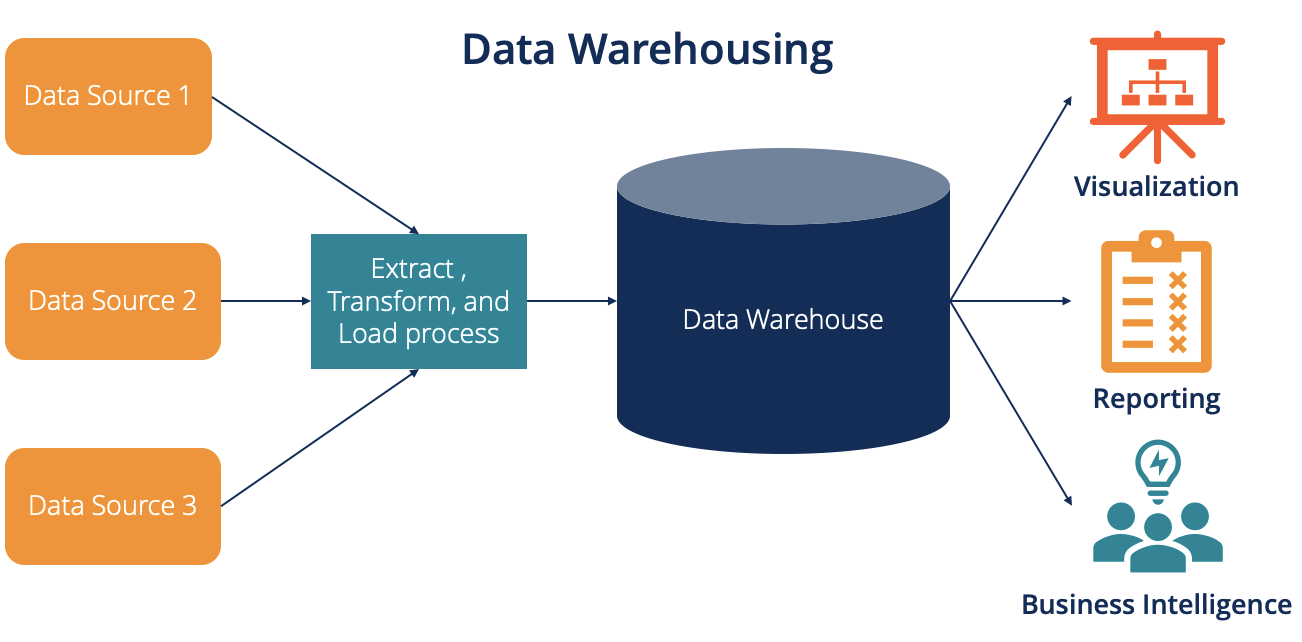
در یک سازمان نرمافزارهای مختلفی قرار دارد که هر کدام دادههایی را تولید میکنند و در فرآیند هوش تجاری بایستی از آنها جهت ایجاد ارزش استفاده کنیم اگر بخواهیم برای هر پرس و جو (Query) که به تحلیل ما کمک کند، به این نرمافزارها درخواستی دهیم، احتمالا وقت و زمان خود را هدر دادهایم. پس بهتر است دادهها را با توجه به موضوعی که میخواهیم تحلیل کنیم در یک مکان انبار کنیم. به این مکان انبار داده (Data Warehouse) میگویند.
انبار داده قلب هوش تجاری است. بدون انبار داده، جریان اطلاعات در سیستم های عملیاتی متوقف میشود. در این شرایط کسب و کار فقط نوک بینی خود را میتواند ببیند. داده ها در سیستم های عملیاتی متولد میشوند اما پرورش و بلوغ آن ها در انبار داده و در لایه بعد از آن روی میدهد. بدون انبار داده، یک کسب و کار فقط سیستم مکانیزه دارد نه هوش تجاری، هوش تجاری بدون انبار داده یک شوخی با ریسک بالا است.

Data Mart بر روی یک ناحیه عملکردی واحد از یک سازمان متمرکز است و شامل زیرمجموعهای از دادههای ذخیره شده در یک Data Warehouse است. Data Mart یک نسخه فشرده از Data Warehouse است و برای استفاده توسط یک بخش، واحد یا مجموعهای از کاربران خاص در یک سازمان طراحی شده است. بهعنوانمثال، بازاریابی، فروش، منابع انسانی یا امور مالی اغلب توسط یک بخش واحد در یک سازمان کنترل میشود.
Data Mart معمولاً دادهها را از منابع کمتری در مقایسه با انبار داده (Data Warehouse) میگیرد. دیتا مارت ها از نظر اندازه کوچک هستند و در مقایسه با Datawarehouse انعطافپذیرتر هستند.
چرا به Data Mart نیاز داریم؟
- Data Mart به دلیل کاهش حجم داده به افزایش زمان پاسخگویی به کاربر کمک میکند.
- دسترسی آسان به دادههای درخواستی را فراهم میکند.
- پیادهسازی Data mart در مقایسه با Datawarehouse سادهتر است. درعینحال، هزینه اجرای Data Mart در مقایسه با اجرای یک انبار داده کمتر است.
- در مقایسه با Data Warehouse، دیتامارت سریعتر است. در صورت تغییر در مدل، دیتامارت به دلیل اندازه کوچکتر میتواند سریعتر ساخته شود.
- Datamart توسط یک کارشناس موضوعی واحد تعریف میشود. برعکس، انبار داده توسط SMEهای میانرشتهای از حوزههای مختلف تعریف میشود. ازاینرو، Data mart در مقایسه با Datawarehouse در قابل تغییر است.
- دادهها پارتیشنبندی شدهاند و اجازه دسترسی بسیار جزئی را میدهند.
- دادهها را میتوان بر روی پلتفرمهای سختافزاری و نرمافزاری مختلف تقسیمبندی و ذخیره کرد.
فرمت فایل Parquet
- این فرمت فایل توسط کلودرا و توییتر در سال ۲۰۱۳ ایجاد شد.
- از ویژگی های منحصر به فرد Parquet این است که می تواند داده ها را با ساختارهای تو در تو به صورت ستونی ذخیره کند. با این وجود فیلدهای تودرتو را می توان به صورت جداگانه و بدون خواندن تمام فیلدهای ساختار تودرتو خواند.
- این فرمت برای کار با حجم عظیمی از داده های پیچیده مناسب است و گزینه های فشرده سازی و رمزگذاری(Encoding) داده های مختلفی را ارائه می دهد.
- این فرمت فایل برای خواندن ستونهای خاص از جداول بزرگ بسیار مفید است، زیرا تنها میتواند ستونهای مورد نیاز را به جای کل جدول بخواند. این امر منجر به پردازش سریعتر دادهها میشود و زمان مراجعه به I/O را کاهش می دهد.
- قابلیت ذخیره سازی ستونی موجب می شود، داده های غیر مرتبط را به سرعت در حین پرس و جو فیلتر کند.
- کدکهای مختلفی برای فشردهسازی دادهها وجود دارد و فایلهای داده میتوانند انواع فشردهسازی متفاوتی داشته باشند.
مشاهده فیلم ضبط شده رویداد
مشاهده فیلم ضبط شده رویداد ویدئو
58:43
دوره های مرتبط

کارگاه آموزشی کاربردهای شگفتانگیز ChatGPT

کارگاه آموزشی آمار و احتمالات ضروری برای علم داده

کارگاه آموزشی پروژه محور مبانی یادگیری عمیق با پایتون

کارگاه آموزشی پروژه محور اصول پردازش زبان طبیعی در پایتون

کارگاه آموزشی متدلوژی توسعه پروژه های تحلیل داده

کارگاه آموزشی پروژه محور شبکه های عصبی گرافی

کارگاه آموزشی پروژه محور Docker برای علم داده



پلتفرم بعنوان سرویس با Docker برای مهندسان داده
امتیاز دانشجویان دوره
نظرات
199,000 تومان

حمید جهانی
دانشمند علم دادهحمید، فارغ التحصیل ارشد Data Science از دانشگاه تربیت مدرس تهران است. حمید بعنوان Business Data Analyst در Digikala فعالیت داشته است و در حال حاضر بعنوان Data Scientist در شرکت Snappfood مشغول به کار است.
تنها اشخاصی که این محصول را خریداری کرده اند و وارد سایت شده اند می توانند در مورد این محصول بازبینی ارسال کنند.