
معرفی ابزارهای کلیدی و مهم در هدوپ
مقدمه
در حال حاضر، یکی از مهم ترین و بزرگ ترین چهارچوب های تحلیلی داده را می توان هدوپ نامید که قلب تپنده بسیاری از پروژه های بیگ دیتا در سطح جهان است. ابتدا سیر تاریخی استارت این پروژه را با هم بررسی می کنیم.
- گوگل فایل سیستم خود را با نام GFS ارائه کرد. 2003
- گوگل در 2004 مقاله مپ ردیوس را ارائه کرد. 2004
- هدوپ ساخته شد. 2006
- هدوپ یک کلاستر 300 ماشینه را استارت زد. 2006
- گوگل مقاله Big Table را ارائه کرد. 2006
- پروژه HBase کلیک خورد. 2006
- یاهو دو تا کلاستر 1000 ماشینی را Run کرد. 2007
- یاهو یه کلاستر 10000 Core CPU برای سرچ ایندکس خود تولید کرد. 2008
- هدوپ رکورد Sort دیتا در دنیا رو با مرتب سازی 1TB دیتا در 209 ثانیه با یه کلاستر 910 تایی زد. 2008
- شرکت Cloudera توزیع اختصاصی هدوپ خود را ارائه کرد. 2008
- گوگل رکورد یاهو را زد و 1TB را در 68 ثانیه Sort کرد.
- دیتابیس HBase به عنوان یک Sub-Project هدوپ شناخته شد. 2008
- یاهو 17 کلاستر را با 24000 ماشین Run کرد. 2009
- یاهو رکورد گوگل را زد و 1TB را در 48 ثانیه Sort کرد. 2009
- دیتابیس HBase جزو Apache Top Project شناخته شد. 2010
- انباره داده Hive جزو Apache Top Project شناخته شد. 2010
- هماهنگ ساز ZooKeeper به عنوان یک Sub-Project هدوپ شناخته شد. 2011
- مدیریت مصرفی منابع با نام YARN ارائه شد. 2013
- هدوپ نسخه 2.2. ارائه شد. 2013
- موتور پردازشی Spark جزو Apache Top Project شناخته شد. 2014

هدوپ
ما در بیگ دیتا بحث توزیع شدگی را داریم که حجم داده ها با آن رابطه مستقیم دارد. یعنی وقت حجم داده ما بیگ باشد که نتوانیم با سیستم ها و سرورها معمول مثل یه San Storage آنها را هندل کنیم نیاز به توزیع دیتا پیدا می کنیم.، چرا که می بایست فضا و توان پردازش بیگ دیتا را داشته باشیم. هدوپ پردازش داده ها را بصورت Batch یا دسته ای انجام می دهد و توانایی پردازش Stream را ندارد.
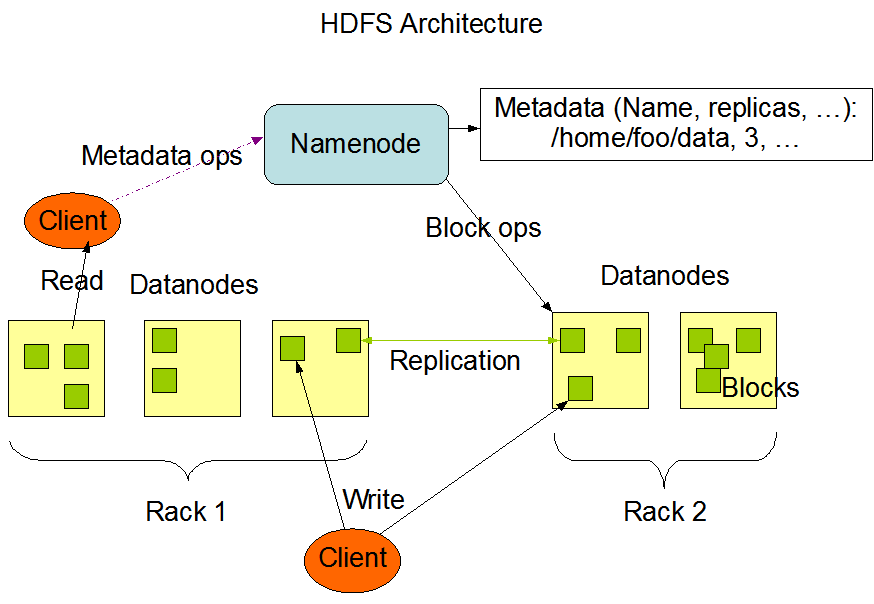
سیستم فایل HDFS
فایل سیستم توزیع شده هدوپ هست چیزی مشابه Google File System – GFS که برای کار با فایل های بزرگ ساخته شده و بلاک سایز پیش فرض آن 64 – 128مگابایت هست. HDFS فایل ها رو به بلوک هایی با اندازه مشخص روی سرورها پخش می کند و روی بلوک ها Replication می گذارد. بعنوان مثال یه فایل 1000 مگابایتی واریز می کنیم به حسابش، اون میاد تقسیمش می کنه به 8 تا فایل 128 مگابایتی که هر بلاکش رو چند تا سرور پخش شده. اجزای HDFS عبارتند از:
- عنصر NameNode: مدیر کلاستر هست.
- عنصر DataNode: اصل کارای پردازش رو اینا انجام میدن که روی دیسک می نویسن و ذخیره و بازیابی میشن، خود کلاینت می تونه بهش دسترسی داشته باشه.
- عنصر Secondary NameNode: تصور نشه اگه NameNode خراب بشه حالا بیخیال Secondary NameNode هست. اگه NameNode دور از جون خراب بشه کل کلاستر میاد پایین و صاف میشیم عملا! در حقیقیت Secondary NameNode میاد سرعت NameNode رو می بره بالا و نقش یه SPoF: Single Point of Failure را ایفا می کند.
در نتیجه ما نیاز به HA: High Availability داریم که در هدوپ نسخه 2 ارائه شد. بدین صورت که ما 2 تا NameNode رو استارت می زنیم که از هم مستقل هستند و ZooKeeper وظیفه مدیریت آنها را بر عهده دارد. یکی از اونها Active و دیگری Standby هستش. نکته جالب اینست که در هدوپ نسخه 3 تعداد NameNode ها 3 تا شده است 🙂
دیتابیس HBase
دیتابیس HBase دسترسی تصادفی به بیگ دیتا رو مشابه Google Big Table فراهم می کند و می تواند روی بستر HDFS بصورت کاملا منطبق با Map Reduce اجرا شود.
هماهنگ ساز ZooKeeper
واقعا از اسمش مشخصه. هدوپ یه باغ وحشه و نیاز به یه نگهبان داره که بتونه کار کردن این همه ابزار رو با هم هندل کنه. پس این نگهبان مدیریت و هماهنگی توزیع شده کلاسترها را بر عهده دارد.
مدیریت اجرای تسک با Oozie
مدیریت اجرای تسک های مبتنی بر مپ ردیوسی را بر عهده دارد.
انباره داده Hive
با ارائه یک پوسته SQL دسترسی به داده های Hadoop را فراهم می کند.
با ارائه یک Manager توکار و پیاده سازی Agent هایی که داراست وظیفه راه اندازی و کانفیگ هدوپ را انجام می دهد.
مطالب زیر را حتما مطالعه کنید

MLOps چیست؟

هوش مصنوعی مولد یا Generative AI چیست؟

چت بات هوش مصنوعی محور ChatGPT که در آینده جایگزین انسان خواهد شد

آشنایی با Graph Attention Network (شبکه های توجه گرافی)

طراحی شبکه های عصبی گرافی با استفاده از کتابخانه PyG در پایتون

دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.