
آپاچی اسپارک برای پردازش و تحلیل کلان داده
مقدمه
دیگه همه مون می دونیم چرا مدل هایی مثل مپ ردیوس بوجود اومدن. علتش همین بیگ دیتا است. دیتامون بیگ میشه، نمی تونیم روی یه سرور جاش بدیم، مجبوریم بریم سمت مقیاس پذیری افقی و Distributed Systems و به امثال San Storage بگیم بای بای. گوگل اعظم اول Google File System – GFS رو ارائه داد و بعدش HDFS از روی همین GFS ساخته شد و بعدش گوگل Big Table رو داد و HBase هم از روی همین BT ساخته شد که چیز خفنیه.
هدوپ و مپ ردیوس
فلسفه کار در مپ ردیوس این است: بجای اینکه دیتا رو روی سرورهامون پخش کنیم میآیم کدمون رو میاریم روی سرورهامون و اجرا می کنیم. گذشته از نحوه اجرای مپ ردیوس که از مپ، شافل و ردیوس تشکیل شده باید گفت کُند هست. علتش هم اینه که دیتا رو از روی HDFS میخونه دوباره توی HDFS قرارش میده و به همین منوال ادامه پیدا می کنه. HDFS هم ذاتا کُند هست چرا؟ چون دیسک بیس هست. در ضمن بصورت پیش فرض باید Replication=3 باشه و همین مزید بر علت میشه. پس از اونجایی که هدوپ دیسک بیس هست نرخ I/O بالایی داره و برای کارهای Batch خوبه و باید بدونیم از Streaming پشتیبانی نمی کنه. ضمنا برای کارهای Iterative مثل الگوریتم های ماشین لرنینگی از جمله خوشه بندی مناسب نیست اونم بخاطر سرعت پایینی که داره. یه نقطه ضعفی که هدوپ داره اینه که برای هرکاری هی ابزار خاص خودشو داره که باعث میشه ملت قاطی کنن خدایی. میخوای کار x انجام بدی برو ابزار xn رو یاد بگیر. همین کارو سخت میکنه. هرکدوم از این ابزارها رو باید نصب کرد که خودش ماجرایی داره بعدش باید یاد گرفت که زمان بره و Maintenance اون هم بحث خاص خودشو داره.

در تصویر زیر مثال معروف و سنتی Word Count رو با استفاده از Map Reduce مشاهده می کنید. یه نکته ای که هست و بعضا دیدم فراموش میشه اینه که فازهای Shuffle and Sort توی MR فراموش میشه. گام های فرآیند MR عبارتند از:
Map > Partition > Shuffle > Sort > Reduce
بعد از اینکه متن ورودی ما در قالب nسطر مجزی شد(کاری که تو فاز اولیه خیلی پروژه های پردازش متن میبینیم) تو فاز Map در واقع یه Key Value درست میشه و ابتدا با نگاشت 1 به همه کلمات کار شروع میشه. ورودی فاز Shuffling در واقع خروجی فاز Map هستش و میاد کلمات یکسان رو ادغام میکنه و کنار هم قرار میده تا بعنوان ورودی بفرسته به فاز Reduce. و تو فاز Reduce هم فرآیند تجمیع مقادیر تکرار کلمات موجود در متن متناظر با کلمات که کلید هستند انجام میشه.
آپاچی اسپارک
اما اسپارک که فاقد لایه Storage هست و از HDFS بعنوان لایه ذخیره سازی استفاده می کنه یه بار دیتای اصلی رو از روی HDFS میخونه و بقیه گام ها رو روی حافظه RAM انجام میده و همین In-Memory بودن اسپارک باعث میشه سرعت بالایی داشته باشه و میل و رغبت ملت 🙂 تو صنعت بره سمتش. ضمنا اسپارک یه موتوره پردازشیه لامبورگینی بیس هستش 🙂 که اکثرا نیازمندی های ما رو در قالب یک چارچوب یکپارچه برطرف می کنه همونطور که خودش اینطور خودشو معرفی میکنه:
Apache Spark™ is a unified analytics engine for large-scale data processing.

تو شکل ذیل هم ماژول های کلیدی اسپارک رو می بینید که در مقالات بعدی مفصل راجع بهشون می نویسم و مثال حل می کنیم باهاشون. همونطور که می بینید تو فیلدهای ذیل ورود کرده که نشان از جامعیت و یکپارچگی اش داره. ملت بدونید پشت هر کدوم از این ابزارها یه مقاله توپ از جاهای خفن دنیا خوابیده در راس اونها دانشگاه کالیفرنیا، برکلی، مهد اسپارک.
- تحلیل گراف: اول GraphX بود و الگوریتم های علم شبکه مثل Page Rank و … رو پشتیبانی میکنه که الآن GraphFrame اومده بیرون که می تونید یه دیتا فریم از گراف بسازید و روش کوئری SQL بزنید. خدایی خفن نیست. رو گرافمون با SQL کوئری بزنیم؟
- یادگیری ماشین: دو تا ماژول MLlib و ML رو داره با یه عالمه الگوریتم، از TF-IDF بگیر تا K-Menas و …
- پردازش Stream: فیت پردازش دیتاهای استریم مثل توییتر و … هست. فرق اسپارک استریم با مپ ردیوس اینه که دیتاهاش بصورت پیوسته و Continuous هست. هرچند واقعا استریم نیست و میکروبچ هستش به این صورت که مثلا میگه برو هر 30 ثانیه یه بار 10000 تا دیتا از اسپارک رو بخون و بیار و روش MR بزن. برخلاف Storm که واقعا استریمه چون میره و دونه دونه دیتا رو میخونه. اما چرا باعث میشه اسپارک سریع تر باشه؟ چون میره یه دفعه یه حجم زیادی از دیتا رو میخونه برمیداره میاره.
- و SQL : می تونیم روی دیتامون کوئری بزنیم که از Hive استفاده می کنه.
معماری اسپارک
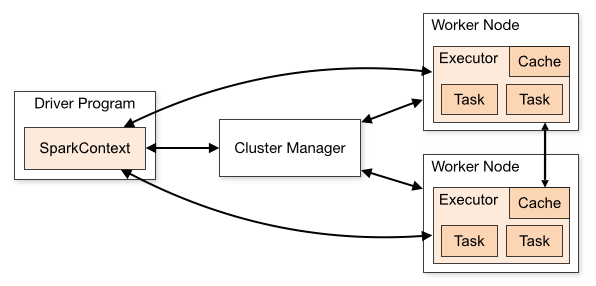
اون کلاستر منیجر که وسط می بینید می تونه یکی از موارد ذیل باشه:
- Spark Standalone (خود اسپارک)
- Apache Mesos
- YARN
کلاستر مینجر میاد چک میکنه چه ورکرهایی داریم چقدر RAM دارن چقدر Core دارن. کلا کارش مدیریت منابع مصرفی مون هست و بقول معروف Resource Manager هستش. یاد سیستم عامل افتادم.
اما دروازه ورود ما به منظور ارتباط برنامه ای که نوشتیم با آپاچی اسپارک Spark Context هستش. به این شکل که آدرس Master رو می دیم به Spark Context که خود SC میره به Master وصل میشه، دیتا رو می گیره و بررسی می کنه Workerها کجا قرار دارن.
این شکل خیلی خوبه. Driver برنامه رو اجرا می کنه. Task ها رو خودش تعریف می کنه اگه به فلش ها دقت کنید. هر Task هم همونطور که می بینید تحت یک JVM اومده بالا. Driver مشخص میکنه که هر Task که تو شکل با T مشخص شده به چه Workerی باید Assign بشه. این هم تو کد ما هست که تو فایل Jar مون وجود داره.
ببینید اون Executor که تو شکل معلومه یه دونه برنامه جاوایی هست. تابلویه دیگه. کنارش زده JVM 🙂 شما وقتی برنامه تون رو Submit می کنید (با Spark-Submit) تو Master Spark، اتومات میاد توی Worker مربوطمون و یه دونه Executor JVM میاره بالا مخصوص برنامه شما.
مهم است بدانیم هر Node و Cluster یه JVM مجزی داره.
مفهوم RDD در اسپارک
بیس و پایه و اساس اسپارک همین مفهوم RDD هستش که اولین APIش هست و بعد از اون Dataset و DataFrame اومدن. RDD درواقع Abstraction اصلی تو اسپارک هستش که به دیتا نگاه می کنه. یعنی چی؟ یعنی وقتی به HBase وصل می شیم می گیم برو دیتا رو بخون بردار بیار به کل دیتای HBase به چشم یه RDD نگاه میکنه. همین سطح انتزاع تو رفتارش باعث سادگی کار ما میشه
اینجا R به Resilient اشاره داره که به انعطاف پذیری اشاره داره. یعنی چی؟ خب ما گفتیم اسپارک بر اساس RAM کار میکنه. حالا یه موقع موشک خورد به RAM و ترکید رفت رو هوا. چی کنیم؟ اینجا R میاد کمکون و می تونه دیتا رو دوباره برامون بسازه.
RDD ها Immutable هستند بر خلاف X-Men که Mutable بودند 🙂
اما Operation ها تو RDD به دو دسته تقسیم میشن:
Action
Transformation
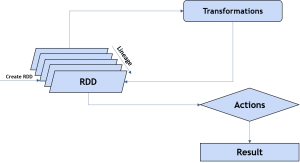
از انواعشون میشه به موارذ ذیل اشاره کرد:
Transformation
Map
Filter
ReduceByKey
و
Action
Collect
Count
Reduce
Take

همونطور که بارها تکرار کردیم اسپارک روی RAM کار میکنه و هر لحظه ممکنه سرور خاموش بشه یا بترکه بره رو هوا و دیتا از روی RAM بپره دود شه بره هوا. اسپارک یه مکانیزمی داره که می تونه RDD رو Persist کنه روی دیسک و هر موقع لازم شد سریع اونو از روی دیسک بخونه و عملیات هاش رو انجام بده. بصورت پیشفرض Persist() میاد دیتا رو تو JVM Heap به عنوان unserialized objects ذخیره میکنه. اگه از Persist استفاده کنیم می تونیم از سطوح ذخیره سازی متعددی مثل
MEMORY_ONLY
MEMORY_AND_DISK
MEMORY_ONLY_SER
MEMORY_AND_DISK_SER
DISK_ONLY
استفاده کنیم.
اما ما می تونیم از Cache هم استفاده کنیم که در این صورت تنها از سطح ذخیره سازی MEMORY_ONLY. بهره مند میشیم.
یه مفهومی هم داریم به اسم Broadcast Variables، وقتی یه چیزی رو می خوایم روی همه سرورها Share کنیم ازش استفاده می کنیم. مثلا می خوایم روی دیتا Map بزنیم یا Filter کنیم.

Directed Acyclic Graph یا گراف جهت دار غیر مُدور
زمانی که ما کدمون رو می زنیم کنسول اسپارک، میره برامون یه گراف عملیاتی می سازه، یه گراف جهت دار غیر مُدوّر معروف به DAG که ملت 🙂 حتما تو طراحی الگوریتم باهاش آشنا شدن. خود Spark UI رو بیارین بالا کامل DAG مربوط به برنامه تون رو بصورت مصورسازی نشون میده.
- هر وقت یه Action روی RDD بزنیم (مثلا Collect)، اسپارک یک DAG میسازه و به DAG Scheduler یا زمانبند DAG ارسال میکنه. DAG Scheduler میاد و Operator که داریم رو به چند تا Stage از Task (یا مراحلی از وظایف) تقسیم بندی می کنه. یه Stage شامل Task هایی هستش که روی پارتیشن داده های ورودی اعمال میشن تشکیل شده. DAG Scheduler میادش عملگرهای مدنظرمون برای اجرا روی دیتا رو با هم پایپ لاین (یا به بدترین ترجمه ممکن روی کره زمین لوله بندی!) میکنه. بعنوان مثال خیلی از Map هایی که میخوایم روی دیتامون بزنیم می تونن تو یه دونه Single Stage توسط DAG Scheduler زمان بندی و برنامه ریزی بشن. در پایان نتیجه نهایی یه DAG Scheduler مجموعه ای از Stage ها هستش.
-
Map1 + Map2 + … + Map n = A Single Stage
-
- در ادامه Stage ها به سمت Task Scheduler ارسال میشن. همین Task Scheduler میاد Task هاش رو از طریق کلاستر منیجر مثل Spark Standalone, Yarn, Mesos میاره بالا. نکته ای که باید توجه داشته باشیم اینه که Task Scheduler هیچ چیزی راجع به وابستگی های بین Stage Dependencies نمی دونه.
- در پایان Worker ها میان Task ها روی Salve ها اجرا میکنن. بعدش یه JVM جدید برای هر Job بصورت مجزی میارن بالا. Worker ها هم فقط از کُدی که از سمت برنامه نویس بهشون پاس داده شده مطلع هستند.
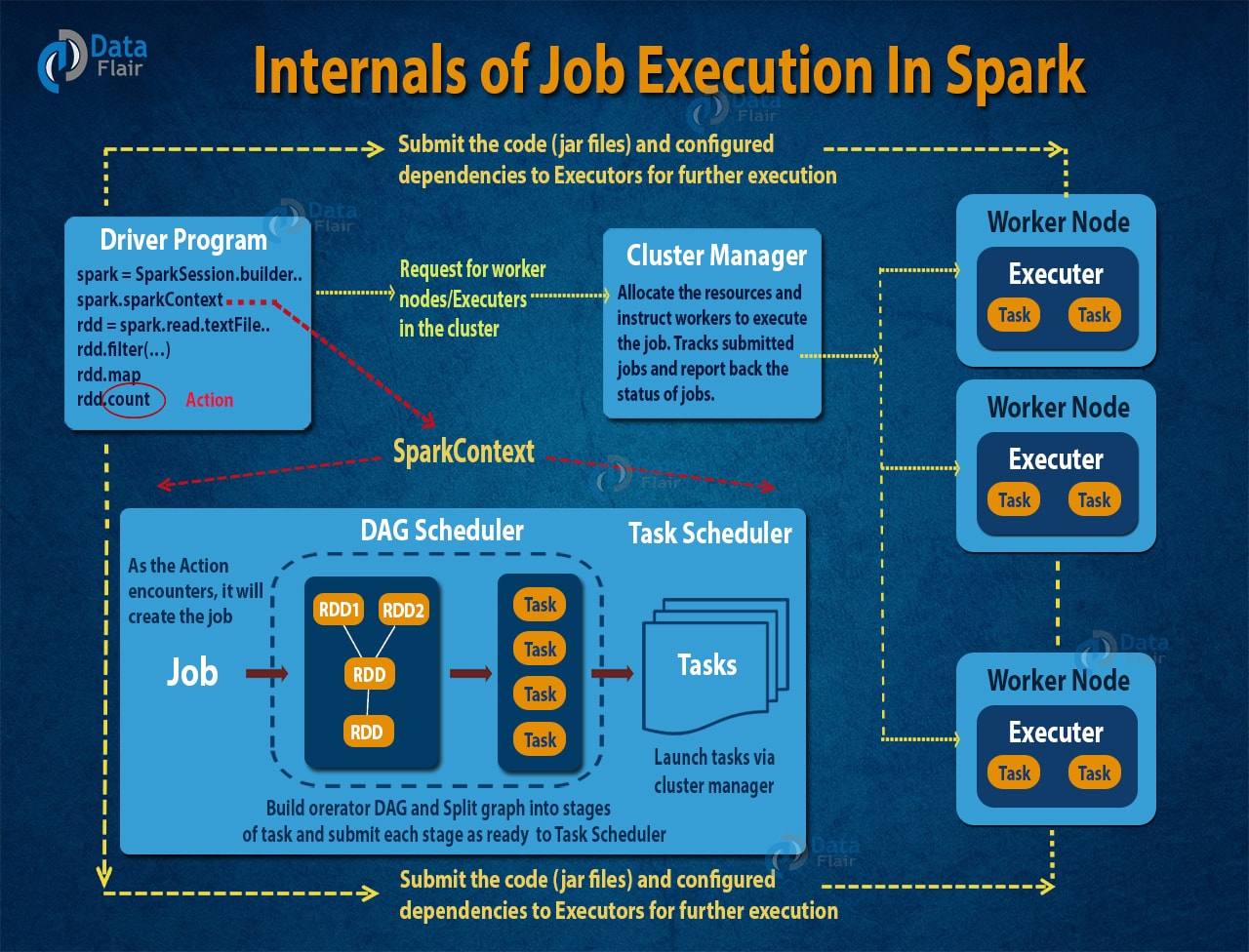
اسپارک چگونه DAG را میسازد؟
ما دو نوع Transformation داریم که می تونیم بزنیم روی RDD هامون:
- Narrow: اینا نیازی به Suffle تو وسط Partition ها ندارن. مثل Map, Filter, …
- Wide: اینا تو لبه های Stage انجام میشن. این تیپ نیاز دارن تا دیتا اول توسط reduceByKey چیی بشه؟ Shuffle بشه (یا یه هَمی بخوره مثل شُله زرد)
یه مثال براتون با Scala زدم و روی یه دیتای تکست یه job کوچولو زدم که می تونید ببینید و یه نکته که نباید فراموش بشه.
تا زمانی که job ساخته نشه هیچ DAG ای ساخته نمیشه.
بعد ساخته شدن job می تونین به اینترفیس اسپارک مراجعه کنید و جزیات ببینید.
Job توسط یه Action فعال میشه، مثل saveAsTextFile یا …
اول از همه من اومدم یه دونه RDD ساختم اما چطوری؟ با صدا زدن متد sc.textFile(). که دیاگرام DAG بدین شکل هست:
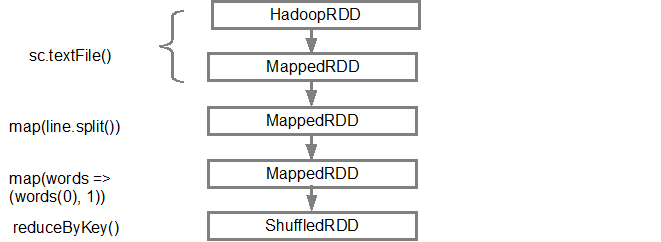
وقتی DAG درست شد، حالا اسپارک میاد یه دونه Physical Plan Executor می سازه. بالاتر هم اشاره کردیم که DAG Scheduler میادگرافمون رو به چندین Stage تقسیم بندی میکنه. حالا Stage ها بر چه اساسی درست میشن؟ بر اساس Transformation. در ادامه Narrow Transformation با همدیگه Pipeline میشن و تشکیل یه Stage رو میدن. برای مثالی که نوشتیم خود اسپارک میاد دو تا Stage درست می کنه به این شکل
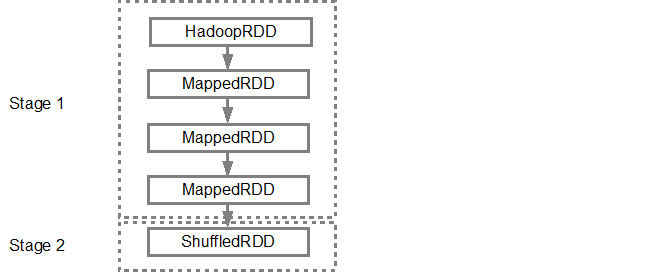
بعدش DAG Scheduler میاد Stageها رو می فرسته سمت Task Scheduler. تعداد Task ها وابسته به تعداد Partitionهاست.
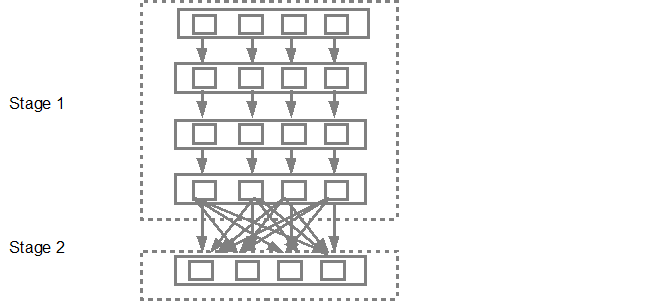
مثال
اینم کُدش و خروجی اش اگه دوست داشتید چک کنید.
scala> val data = sc.textFile(“test.txt”)
data: org.apache.spark.rdd.RDD[String] = test.txt MapPartitionsRDD[1] at textFile at <console>:24scala> val split = data.map(data => data.split(“”)).
| map(words => (words(0), 1)).
| reduceByKey
reduceByKey reduceByKeyLocally
| reduceByKey((a,b) => a+b).
| toDebugString
split: String =
(2) ShuffledRDD[4] at reduceByKey at <console>:27 []
+-(2) MapPartitionsRDD[3] at map at <console>:26 []
| MapPartitionsRDD[2] at map at <console>:25 []
| test.txt MapPartitionsRDD[1] at textFile at <console>:24 []
اسپارک چطور از هدوپ استفاده می کند؟
نکته مهمی که می بایست مورد توجه قرار گیرد اینست که هدوپ یک اکوسیستم پردازش کلان داده است که ابزارهای متنوعی می توانند در این اکوسیستم حضور داشته باشند و با هدوپ کار کنند. یکی از این ابزارها موتور پردازشی یکپارچه اسپارک است که به منظور دسترسی به لایه ذخیره سازی داده در فایل سیستم HDFS می تواند با هدوپ یکپارچه شود.
لایه ذخیره سازی داده
اسپارک به تنهایی دارای لایه ذخیرهسازی و ماندگاری داده نیست و میبایست دادهها یا به صورت محلی وارد این ابزار شوند و یا اینکه از فایل سیستم توزیعشده هدوپ و یا Amazon S3 استفاده کنند.
زمان بندی وظایف پردازشی
اسپارک وظایف پردازشی خودش را به صورت تک سیستمی زمانبندی میکند و از روشهای دیگر زمانبندی وظایف پشتیبانی نمیکند.
Yarn وارد می شود و به کمک این موتور پردازشی در جهت زمانبندی توزیعشده وظایف آن میشتابد.
یک دیتابیس؟!
هدوپ نه به تنهایی و با کمک Hive یا Hbase می تواند نقش یک دیتابیس را ایفا کند.
اما اسپارک به دلیل نداشتن لایه ذخیرهسازی به خودی خود نمیتواند نقش یک دیتابیس را بازی کند.
پردازش استریم داده
در مقابل اگر اسپارک را به هدوپ متصل کنید میتوانید دادهها را به صورت درونحافظهای و استریم پردازش کنید.
مطالب زیر را حتما مطالعه کنید

MLOps چیست؟

هوش مصنوعی مولد یا Generative AI چیست؟

چت بات هوش مصنوعی محور ChatGPT که در آینده جایگزین انسان خواهد شد

آشنایی با Graph Attention Network (شبکه های توجه گرافی)

طراحی شبکه های عصبی گرافی با استفاده از کتابخانه PyG در پایتون

متاورس و هوش مصنوعی
دوره های آموزشی مرتبط



2 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.
ممنون مهندس خیلی عالی بود. موفق باشید
درود بر شما