
چرخه حیات ابزارهای کلیدی اکوسیستم بیگ دیتا
مقدمه
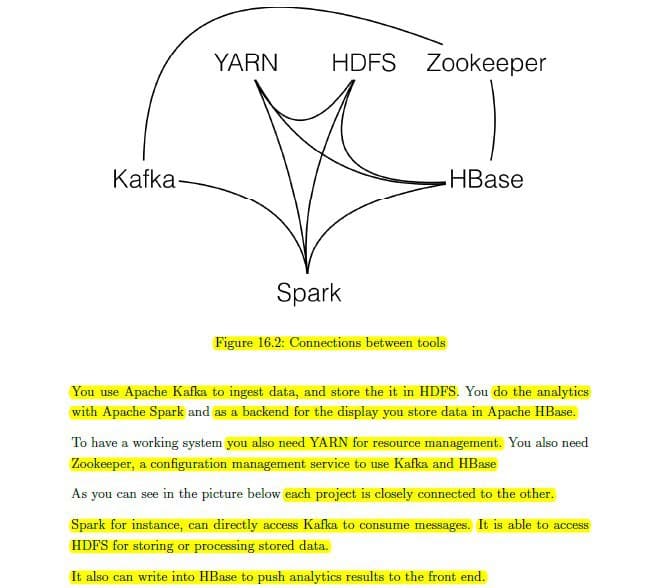
در تصویر، ارتباطات ابزارهای کلیدی اکوسیستم بیگ_دیتا به همراه توضیحات تکمیلی تصویر کشیده شده است.
از آپاچی کافکا به منظور دریافت و ذخیره سازی داده در HDFS استفاده می شود.
به منظور انجام تحلیل های مدنظر از اسپارک کمک می گیریم و در این میان نقش کتابخانه های SQLlib, MLlib, GraphX حیاتی است.
ذخیره سازی داده در دیتابیس ترکیبی HBase صورت می گیرد که در بسیاری از ارگان ها و استارتاپ های کشور دیدم به این دیتابیس مهاجرت کردن
یارن_Yarn که در Map Reduce V2.0 حاضر است، وظیفه مدیریت منابع سیستمی را بر عهده دارد.
به منظور استفاده از HBase و Kafka بالابودن سرویس Zookeeper حیاتی هست که نقش مدیریت کانفیگ سیستم رو انجام میده.
همونطور مشخص هست، این ابزارها ارتباط نزدیک و تنگاتنگی با هم دارن. به عنوان مثال اسپارک برای دریافت پیام ها به صورت مستقیم به کافکا وصل میشه و برای دسترسی و ذخیره سازی دیتا می تونه از HDFS استفاده کنه.
همچنین می تونه نتایج تحلیل دیتا رو بریزه توی HBase تا کاربر نهایی بتونه اونا رو مشاهده کنه.
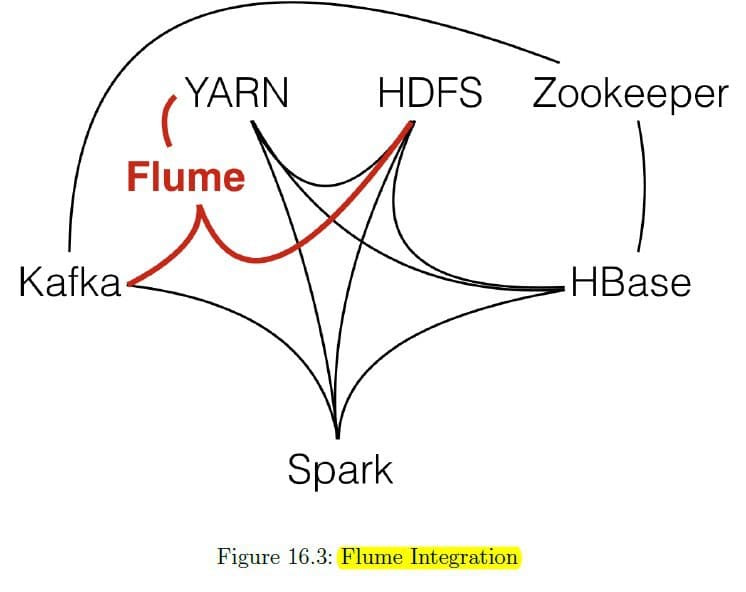
آپاچی فلوم Flume
برای ذخیره سازی دیتا از کافکا به HDFS حضور اسپارک ضروری نیست. پروژه ای به نام فلوم توسعه داده شده است که می تواند به عنوان اینترفیس برای کافکا و HDFS استفاده شود. آپاچی فلوم می تواند به عنوان یک Agent عمل کند و داده ها را از کافکا بصورت مستقیم بخواند و آنها را در HDFS ذخیره کند. فلوم می تواند خارج از چهارچوب رسمی از Yarn جهت مدیریت منابع سیستمی استفاده کند.
مطالب زیر را حتما مطالعه کنید

MLOps چیست؟

هوش مصنوعی مولد یا Generative AI چیست؟

چت بات هوش مصنوعی محور ChatGPT که در آینده جایگزین انسان خواهد شد

آشنایی با Graph Attention Network (شبکه های توجه گرافی)

طراحی شبکه های عصبی گرافی با استفاده از کتابخانه PyG در پایتون

دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.