
داده کاوی یا گراف کاوی در پایتون و اسپارک با Spark GraphFrames
آشنایی با GraphFrames
گراف فریم ها هم مشابه گراف ایکس فرآیند تحلیل و پردازش گراف های حجیم رو انجام میدن اما چون بر مبنای DataFrames هستند بر خلاف گراف ایکس که مستقیما سوار بر RDD هست یه سری مزایا دارن:
- پشتیبانی از رابط های Python, Java & Scala
- امکان ایجاد پرس و جوهای قدرتمند بر بستر Spark SQL و DataFrames
- امکان ذخیره و بارگزاری گراف: گراف فریم ها از دیتاسورس های دیتافریم به طور کامل پشتیبانی می کنن. به همین خاطر ما می تونیم گرافمون رو با استفاده از فرمت های مختلف مثل Parquet, JSON, CSV بخونیم و بنویسیم.
در گراف فریم گره ها و یال ها در قالب دیتافریم ذخیره میشن و ما می تونیم هر نوع داده ای که داریم رو روی هر گره و یالی ذخیره کنیم.

ساخت گراف فریم
ما می تونیم گراف فریم رو بر اساس دیتافریم رئوس و یالهایی که داریم بسازیم. پس شد:
- یه Vertex DataFrame: دیتافریمی هست که یه ستون به نام “id” داره که unique IDs رو به ازای هر راس در گراف تو خودش داره.
- یه Edge DataFrame: دیتافریمی هست که باید دو تا ستون “src”و “dst” داشته باشن. منظور از این دو تا ستون هم مبدا و مقصد گره مون هست که قراره توی گرافمون Traverse کنه.
یه گراف حتی می تونه از یه single DataFrame ساخته باشه که فقط لیست یال ها (edge information.) رو تو خودش داره.

تو این بخش می خوایم یه گراف فریم از دیتافریم ها رئوس و یالهامون بسازیم.
قطعه کد اسکالا
importorg.graphframes.GraphFrame
valv =sqlContext.createDataFrame(List(
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
("d", "David", 29),
("e", "Esther", 32),
("f", "Fanny", 36),
("g", "Gabby", 60)
)).toDF("id", "name", "age")
vale =sqlContext.createDataFrame(List(
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
("f", "c", "follow"),
("e", "f", "follow"),
("e", "d", "friend"),
("d", "a", "friend"),
("a", "e", "friend")
)).toDF("src", "dst", "relationship")
valg =GraphFrame(v, e)
قطعه کد پایتون
v =sqlContext.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
("d", "David", 29),
("e", "Esther", 32),
("f", "Fanny", 36),
("g", "Gabby", 60)
], ["id", "name", "age"])
e =sqlContext.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
("f", "c", "follow"),
("e", "f", "follow"),
("e", "d", "friend"),
("d", "a", "friend"),
("a", "e", "friend")
], ["src", "dst", "relationship"])
g =GraphFrame(v, e)
این گراف فریمی که ساختیم تو GraphFrames package به این صورت در دسترس هست
fromgraphframes.examples importGraphs
g =Graphs(sqlContext).friends()
کوئری روی گراف با طعم SQL 🙂
برای من که چند سالی هست روی گراف کار میکنم این یه خبر خوبه. از یه طرف خیلی از ما خیلی وقت هست با SQL کار کردیم و حالا می تونیم روی مسائل گراف ازش استفاده کنیم. نیازی نیست مثل Neo4j بریم حتما Cypher کار کنیم هرچند اونم بجاش ارزشمنده و قدرتمند.
قطعه کد اسکالا
importorg.graphframes.{examples,GraphFrame}
valg:GraphFrame =examples.Graphs.friends
g.vertices.show()
// +--+-------+---+
// |id| name|age|
// +--+-------+---+
// | a| Alice| 34|
// | b| Bob| 36|
// | c|Charlie| 30|
// | d| David| 29|
// | e| Esther| 32|
// | f| Fanny| 36|
// | g| Gabby| 60|
// +--+-------+---+
g.edges.show()
// +---+---+------------+
// |src|dst|relationship|
// +---+---+------------+
// | a| b| friend|
// | b| c| follow|
// | c| b| follow|
// | f| c| follow|
// | e| f| follow|
// | e| d| friend|
// | d| a| friend|
// | a| e| friend|
// +---+---+------------+
importorg.apache.spark.sql.DataFrame
valvertexInDegrees:DataFrame =g.inDegrees
g.vertices.groupBy().min("age").show()
valnumFollows =g.edges.filter("relationship = 'follow'").count()
قطعه کد پایتون
fromgraphframes.examples importGraphs
g =Graphs(sqlContext).friends()
g.vertices.show()
# +--+-------+---+
# |id| name|age|
# +--+-------+---+
# | a| Alice| 34|
# | b| Bob| 36|
# | c|Charlie| 30|
# | d| David| 29|
# | e| Esther| 32|
# | f| Fanny| 36|
# | g| Gabby| 60|
# +--+-------+---+
g.edges.show()
# +---+---+------------+
# |src|dst|relationship|
# +---+---+------------+
# | a| b| friend|
# | b| c| follow|
# | c| b| follow|
# | f| c| follow|
# | e| f| follow|
# | e| d| friend|
# | d| a| friend|
# | a| e| friend|
# +---+---+------------+
vertexInDegrees = g.inDegrees
g.vertices.groupBy().min("age").show()
numFollows = g.edges.filter("relationship = 'follow'").count()
زیرگراف
تو گراف ایکس برای پیدا کردن یه زیرگراف از متد subgraph() کمک می گرفتیم به این شکل
(یال، گره مبدا، گره مقصد).
اما گراف فریم میاد خیلی قوی تر عمل می کنه و برای پیدا کردن یه زیرگراف، موتیف یابی + فیلترهای دیتافریم رو با هم ترکیب می کنه. ما از سه تا متد کمکی واسه پیدا کردن زیرگراف بهره می بریم:
filterVertices(condition), filterEdges(condition), dropIsolatedVertices.
که به ترتیب میان رئوس مدنظر، یالهای مدنظر رو انتخاب می کنن و فیلتر می زنن روش و رئوس ایزوله رو حذف میکنن. تو بخش اول یه زیرگراف ساده رو با استفاده از vertex and edge filters پیدا می کنیم به این شکل
قطعه کد اسکالا
importorg.graphframes.{examples,GraphFrame}
valg:GraphFrame =examples.Graphs.friends
// Select subgraph of users older than 30, and relationships of type "friend".
// Drop isolated vertices (users) which are not contained in any edges (relationships).
valg1=g.filterVertices("age > 30").filterEdges("relationship = 'friend'").dropIsolatedVertices()
یک مثال شبکه های اجتماعی
ما یه سری کاربر داریم که با هم در ارتباطن که مشخصه. یه سری سوالات مثل:
- کدوم کاربر تو شبکه از همه تاثیرگذار تره؟
- کاربر الف و ب همدیگرو نمی شناسن اما امکانش هست اونا رو با هم آشنا کنی؟
این تیپ سوالاتو می شه با گراف بهش رسید و جواب داد.
گراف فریم هم می تونه دیتاها رو در قالب گره و یال ذخیره کنه که تو مثال ما هر کاربر نام و سن بخصوص داره و تو شبکه ها با هم در ارتباطن
کوئری های ساده
با گراف فریم، کوئری زدن خیلی آسونه (به لطف دیتافریم). چرا که گره و یال تو دیتافریم ذخیره میشن و خیلی کوئری هامون فقط کوئری های (SQL) دیتافریم هستند. با هم یه مثال ساده رو بررسی می کنیم و می خوایم بدونیم کدوم کاربر سنش بیشتر 35 هست؟ می تونیم روی گره های گراف اینطوری کوئری بزنیم:
graph.vertices.filter("age>35")
یه مثال دیگه و اون اینکه کدوم کاربرها حداقل 2 تا Follower دارن؟ ما می تونیم مجموع درجات ورودی رو با هم ترکیب کنیم و به جواب برسیم.
graph.inDegrees.filter(“inDegree>=2”)
کوئری های متوسط
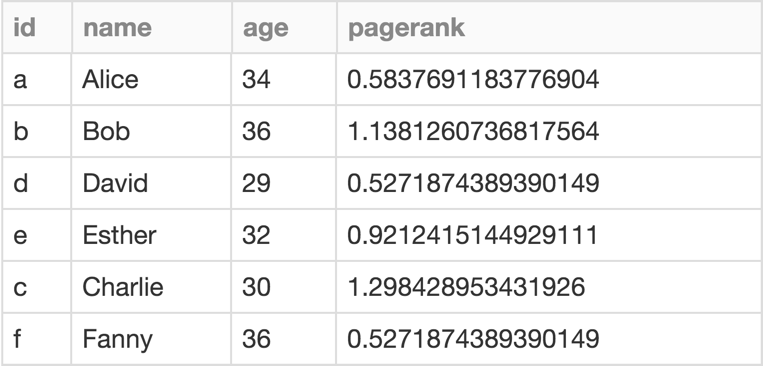
گراف فریم همه الگوریتم های موجود در گراف ایکس رو روی Scala, Java, Python ساپورت میکنه. خروجی یه الگوریتم روی گراف یا دیتافریم هستش یا گراف فریم. بعنوان مثال ما میخوایم بدونیم مهمترین شخص تو شبکه مون کیه؟ میآیم از الگوریتم PageRank معروف گوگل کمک می گیریم. خروجی ما هست:
results = g.pageRank(resetProbability=0.15, maxIter=10)
display(results.vertices)
الگوریتم هایی که گراف فریم ازشون پشتیبانی میکنه
- الگوریتم PageRank: واسه شناسایی گره های مهم تو گراف
- الگوریتمShortest paths: پیدا کردن کوتاه ترین مسیر
- الگوریتمConnected Components: گروه بندی راس ها به زیرگروه های متصل
- الگوریتمStrongly Connected Components: سافت ورژن مورد شماره 3
- الگوریتمTriangle Count: واسه شمارش تعداد دفعاتی که راس عضو سه تایی هاست.
- الگوریتمLabel Propagation Algorithm – LPA واسه تشخیص اجتماعات
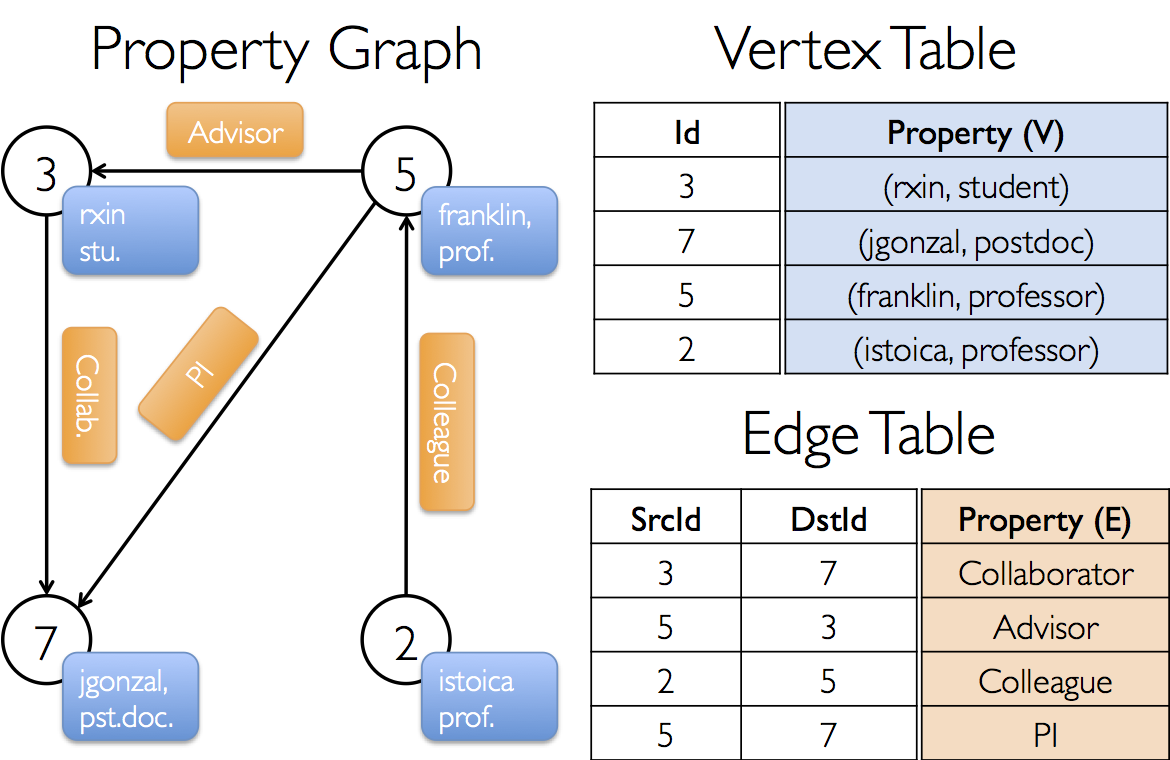
مقایسه GraphFrames و GraphX

جداول گره ها و یال ها در گراف ایکس
مصورسازی فرآیند موتیف مچینگ در گراف
در ادامه
می تونید پکیج گراف فریم رو از اینجا دانلود کنید. اینم گیت هاب گراف فریم.
فقط یادتون نره قبل شروع اینو لود کنید و حتما باید اسپارک ترجیحا نسخه های جدیدتر روی سیستم تون نصب باشه البته فعلا Preview نصب نکنین
$SPARK_HOME/bin/spark-shell –packages graphframes:graphframes:0.8.0-spark3.0-s_2.12
مطالب زیر را حتما مطالعه کنید

MLOps چیست؟

هوش مصنوعی مولد یا Generative AI چیست؟

چت بات هوش مصنوعی محور ChatGPT که در آینده جایگزین انسان خواهد شد

آشنایی با Graph Attention Network (شبکه های توجه گرافی)

طراحی شبکه های عصبی گرافی با استفاده از کتابخانه PyG در پایتون

دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.