
آشنایی با اجزای اکوسیستم هدوپ برای تحلیل کلان داده ها
مقدمه
تو این بخش میخوایم با اکوسیستم، چارچوب، فریم ورک یا اسم هایی از این نوع پیرامون هدوپ بیشتر آشنا بشیم. به احتمال زیاد تصاویر و شماتیک های متعددی از ساختار هدوپ دیدید اما یه نکته ای که باید تو این ساختار توجه داشت این هستش که باید بدونیم تمام ابزارهای موجود در چارچوب هدوپ مبتنی بر نمودار لایه ای هستند به این شکل که مولفه ها و ابزارها از قابلیت های مولفه ها و ابزارهایی که در پایین شون قرار دارن استفاده میکنن، پس ارتباط بهره وری بصورت عمودی از بالا به پایین هست و معمولا به صورت افقی با هم ارتباط ندارن.

اما لایه ای زیرین بیشتر متمرکز بر ذخیره سازی و زمان بندی هستن و لایه های بالایی تمرکزشون بر زبان های برنامه نویسی و تعامل پذیری بیشتر با کاربر نهایی هست. نکته مهمی که در باب ذخیره سازی بهش توجه می کنیم اتکاری چارچوب هدوپ بر فایل سیستم اختصاصی خودش یعنی HDFS هست که دو تا ویژگی مهم داره:
- مقیاس پذیری بالا و قابلیت اطمینان
- قابلیت تحمل خطا
اما همونطور که مشاهده می کنید YARN سوار بر HDFS دو وظیفه کلیدی رو به دوش میکشه:
- زمان بندی انعطاف پذیر
- مدیریت منابع
جالبه بدونید یارن زمان بندی جاب ها روی بیش از 40000 سرور در یاهو انجام میداده.
مپ ردیوس
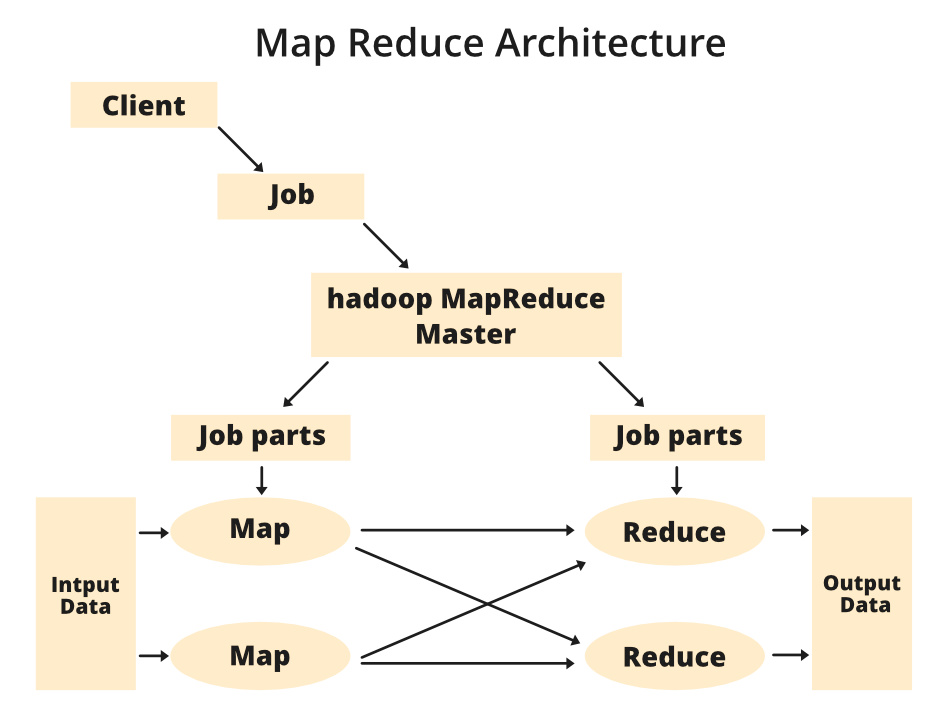
اما این وسط مپ ردیوس چی کارست؟ مپ ردیوس هم سوار بر یارن هستش و از قابلیت هاش استفاده میکنه. گوگل برای ایندکس صفحات وبش از مپ ردیوس استفاده میکنه. همین مساله اهمیت این مدل ساده شده برنامه نویسی رو می رسونه که میاد از دو تابع کلیدی استفاده میکنه:
- Map: Apply()1
- Reduce: Summarizer()2
البته مپ ردیوس به این سادگی ها نیست و تو یه پست مجزی مفصل بهش می پردازم که این مدلی که گوگل ارایه کرده چطور کار میکنه. تو لایه های بالا هم Pig و Hive میان از HDFS و مپ ردیوس استفاده میکنن. در رابطه با Pig, Hive هم باید مجزی صحبت کنم. پیگ به عنوان یه زبان گردش کار تو یاهو دولوپ شده بعدا اهدا شده به بنیاد آپاچی و هایو هم به منظور اجرای پرس و جو با استفاده از مپ ردیوس روی دیتاهای مبتنی بر HDFS تو فیس بوک.
ابزارهایی مثل Giraph, Strom, Spark, Flink هم سوار بر YARN, HDFS هستند و ذخیره ساز HBASE هم سوار بر HDFS. دیتابیس هایی مثل Cassandra , MongoDB هم به صورت لایه Cross Cut به شکل عمودی می تونن کنار چارچوب قرار بگیرن.
یه نکته هم راجع به Strom, Spark, Flink بگم،اینا به صورت Real time & in Memory Processing هستند و برای بعضی تسک ها تا 100 برابر سریع تر عمل می کنند. اما این Zookeeper چیکارست که به صورت یه لایه Cross cut اون کنار تمامی لایه ها حضور داره از hdfs تا لایه های بالا؟ زوکیپر میاد همگام سازی سرویس های مختلف رو انجام میده و وظیفه پیکره بندی سرویس ها رو به عهده داره از جمله گروه بندی و نامگذاری اونها. مزیت زوکیپر این هستش که میاد به کلاسترها کمک میکنه تا با کاهش تاخیر و افزایش دسترسی پذیری پیچیدگی مدیریتی شون کاهش پیدا کنه.

مطالب زیر را حتما مطالعه کنید

MLOps چیست؟

هوش مصنوعی مولد یا Generative AI چیست؟

چت بات هوش مصنوعی محور ChatGPT که در آینده جایگزین انسان خواهد شد

آشنایی با Graph Attention Network (شبکه های توجه گرافی)

طراحی شبکه های عصبی گرافی با استفاده از کتابخانه PyG در پایتون

متاورس و هوش مصنوعی
دوره های آموزشی مرتبط





دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.