

دنیای اسپارک
دنیای همیشه متصل ما، با ایجاد داده ها با سرعتی بیشتر از آنچه قانون مور می تواند ایجاد کند، باعث می شود که ما در تصمیم گیری در مورد چگونگی تحلیل آن ها هوشمندانه عمل کنیم. قبلاً ما فریمورک MapReduce Hadoop را برای پردازش دسته ای داشتیم، اما تقاضای مدرن پردازش کلان داده ها، این فریمورک را پشت سر گذاشته است. اینجا همان جایی است که Apache Spark وارد عمل می شود، با سرعت 10-100 برابر سریعتر از Hadoop و در کسب رکورد جهانی مرتب سازی در مقیاس بزرگ به خود می بالد. انتزاع عمومی Spark به این معنی است که می تواند فراتر از پردازش دسته ای ساده گسترش یابد که آن را قادر به مواردی مانند الگوریتم های سریع، تکراری و جریان معنایی دقیقاً یک بار می کند.
آشنایی با آپاچی اسپارک
آپاچی اسپارک یک چارچوب رایانش توزیعشده متنباز است. این نرمافزار در ابتدا توسط دانشگاه کالیفرنیا، برکلی توسعه داده میشد که بعدها کد آن به بنیاد نرمافزار آپاچی هدیه گردید که از آن زمان توسط آنها نگهداری میشود. اسپارک یک رابط برنامهنویسی کاربردی برای برنامهنویسی تمام خوشهها با موازیسازی دادههای ضمنی و تحمل خطا فراهم میکند.
اسپارک از حافظه اصلی برای نگهداری دادههای برنامه استفاده میکند که این امر باعث سریعتر اجرا شدن برنامهها میشود (برخلاف مدل نگاشت/کاهش که از دیسک به عنوان مکان ذخیرهسازی دادههای میانی استفاده میکند). همچنین یکی دیگر از مواردی که باعث افزایش کارایی اسپارک میشود، استفاده از مکانیسم حافظه نهان هنگام استفاده از دادههایی است که قرار است دوباره در برنامه استفاده شوند. اینکار باعث کاهش سربار ناشی از خواندن و نوشتن از دیسک میشود. یک الگوریتم برای پیادهسازی در مدل نگاشت/کاهش، ممکن است به چندین برنامه مجزا تقسیم شود و در هنگام اجرا هر بار باید دادهها از دیسک خوانده شده، پردازش شوند و دوباره در دیسک نوشته شوند. اما با استفاده از مکانیسم حافظه نهان در اسپارک، دادهها یکبار از دیسک خوانده میشوند و در حافظه اصلی کَش میشوند و عملیاتهای متفاوت بروی آن اجرا میشود. در نتیجه استفاده از این روش نیز باعث کاهش چشمگیر سربار ناشی از ارتباط با دیسک در برنامهها و بهبود کارایی میشود
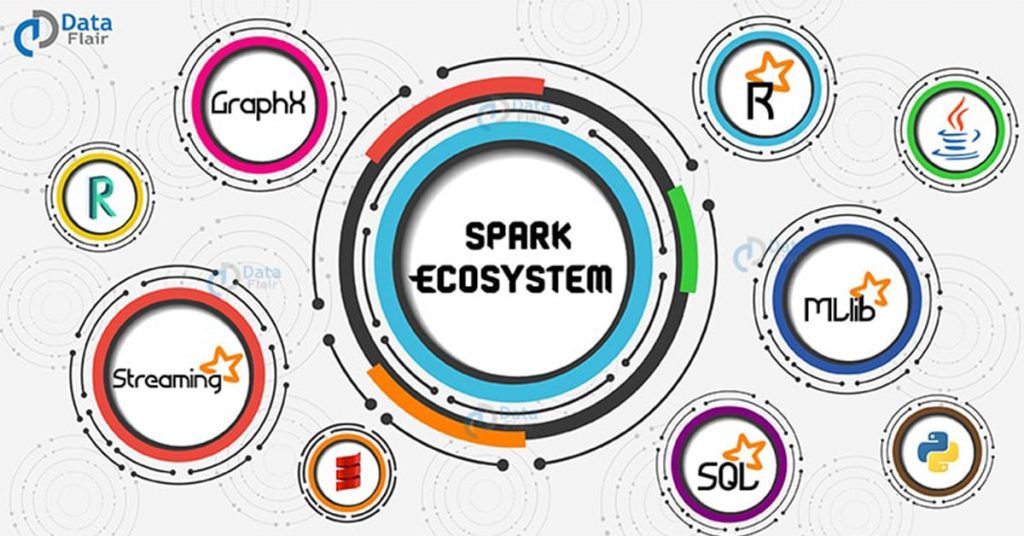
مولفههای اسپارک
در ادامه با مولفه های اسپارک بیشتر آشنا می شویم.
Spark Core
هسته اسپارک حاوی عملیاتهای اولیه اسپارک از جمله اجزای موردنیاز برای زمانبندی وظایف، مدیریت حافظه، مقابله با خطا، تعامل با سیستم ذخیرهسازی و … میباشد . هسته اسپارک همچنین محل توسعه APIهایی میباشد کهRDDها را تعریف میکنند و RDDها مفهوم اصلی برنامهنویسی اسپارک میباشند. RDDها نشانگر مجموعهای از آیتمها هستند که بر روی گرههای محاسباتی متعدد توزیع شده و میتوان آنها را به صورت موازی پردازش کرد. هسته اسپارک APIهای متعددی را برای ایجاد و دستکاری این مجموعهها ارائه میدهد.
Spark SQL
اسپارک SQL چهارچوبی برای کار کردن با دادههای ساختیافته و دارای ساختار میباشد. این سیستم پرسوجو دادهها را از طریق SQL و همچنین آپاچی هایو، نوع دیگر SQL که HQL نیز نامیده میشود، امکانپذیر ساخته و از منابع داده از جمله جداول هایو، ساختار دادههای Parquet،CSV و JSON پشتیبانی میکند. علاوه بر ارائه یک رابط کاربری SQL برای اسپارک، اسپارک SQL توسعه دهندگان را قادر میسازد تا پرسوجوهای SQL را با عملیاتهای تغییر دادهها بروی RDDها که در پایتون، جاوا و اسکالا پشتیبانی میشود، ترکیب کرده و در یک برنامه پرسجوهای SQL را با تحلیلهای پیچیده منسجم کرد. این انسجام نزدیک با محیط پردازشی ارائه شده توسط اسپارک، اسپارک SQLرا از سایر ابزارهای انبار داده متن باز متمایز میکند.
Spark Streaming
مولفه پردازش دادههای جریانی اسپارک یکی از اجزای اسپارک است که پردازش جریان دادهها را فراهم میآورد. از نمونههای جریان دادهها میتوان به فایلهای لاگ ایجاد شده توسط سرورهای وب یا مجموعه پیامهای حاوی به روز رسانی وضعیت ارسال شده توسط کاربران یک وب سرویس و یا در شبکههای اجتماعی نظیر ارسال کردن یک پست اشاره کرد. این مؤلفه APIهایی را برای تغییر جریانهای داده که با APIهای مربوط به RDDهای موجود در هسته اسپارک همخوانی دارد، ارائه میدهد و این امر موجب تسهیل توسعه برنامه برای توسعهدهندگان و سوییچ بین برنامههایی که دادهها را در حافظه اصلی، بر روی دیسک و یا در زمان واقعی پردازش میکنند، میشود. در معماری توسعه این APIها، به منظور برخورداری از قابلیت تحمل خطا، بهرهوری بالا و مقیاس پذیری، همانند مؤلفه هسته اسپارک به نکات مربوط به توسعه سیستمهای توزیع شده توجه شدهاست.
MLlib
اسپارک دارای کتابخانهای متشکل از APIهای یادگیری ماشین (ML) با نام MLlib میباشد. MLlib انواع مختلفی از الگوریتمهای یادگیری ماشین از جمله طبقهبندی، تحلیل رگرسیون، خوشهبندی و پالایش گروهی را ارائه میدهد و همچنین از قابلیتهای مثل ارزیابی مدل و ورود دادهها پشتیبانی میکند. MLlib همچنین ساختارهای سطح پایین یادگیری ماشین مثل الگوریتم بهینهسازی گرادیان نزولی را فراهم میآورد. تمام این روشها با منظور اجرا کردن این برنامهها در سطح کلاستر اسپارک طراحی شدهاند.
GraphX
GraphX یک کتابخانه برای پردازش گرافها و انجام پردازشهای موازی بروی دادههای گراف میباشد. GraphX همانند مؤلفههای اسپارک استریمینگ و اسپارک SQL، APIهای RDDها را توسعه داده و ما را قادر میسازد تا گرافهای جهتدار با نسبت دادن مشخصات به هر گره و یال ایجاد کنیم. GraphX همچنین عملگرهای مختلفی را برای تغییر گرافها (نظیر subgraph و mapVertices) و کتابخانهای از الگوریتمهای گراف (نظیر PageRank و شمارش مثلثهای گراف) فراهم آورده است[۳].
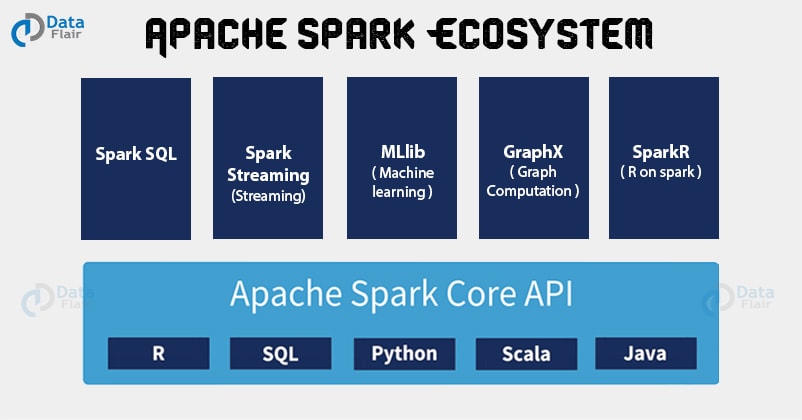
مقدمه
هدوپ Hadoop و اسپارک Spark دو تکنولوژی ذخیره سازی داده های حجیم در پایگاه های nosql هستند. این دو تفاوت های عمده ای با یکدیگر دارند که در ادامه به طور مختصر در مورد هر کدام صحبت خواهیم کرد.
هدوپ Hadoop یک فریمورک مدیریت و پردازش کلان داده به صورت توزیع شده می باشد که در آن داده های بزرگ به داده های کوچک شکسته می شوند. استفاده از هدوپ راهی آسان برای گسترش داده های مورد نیاز یک شرکت را فراهم می کند و به MapReduce اجازه می دهد تا وظایف خود را بر روی مجموعه های کوچکتر داده به منظور پردازش سریع تر انجام دهد. لازم به ذکر است که هدوپ می تواند از انواع داده ها پشتیبانی کند.
اسپارک Spark یک موتور پردازشی توزیع شده و درون حافظه ای است که با هدف استفاده حداکثری از مموری برای کوئری و تحلیل داده به وجود آمده است. اسپارک قابلیت بسیار بالایی در پردازش داده ها با استفاده از یادگیری ماشین دارد. برخی از فعالین این حوزه مدعی هستند که سرعت پردازش آپاچی اسپارک چیزی در حدود 100 برابر بیشتر از هدوپ است. اسپارک نیز مانند هدوپ قابلیت استفاده از ETL و یکپارچه کردن دیتا را دارد.
در این دوره چه مباحثی آموزش داده شده است؟
در دوره آموزشی مفاهیم بنیادی پردازش و مدیریت بیگ دیتا، به معرفی اکوسیستم هدوپ و موتور پردازشی توزیع شده آپاچی اسپارک می پردازیم. هدف این دوره آموزشی پرداختن به مباحث پایه ای در حوزه ابزارهای اکوسیستم هدوپ جهت احراز نیازمندی های مشاغل Data Engineer و Data Scientist می باشد.
سرفصل های دوره آموزش مفاهیم کلیدی هدوپ Hadoop و اسپارک Spark
-
آشنایی با بیگ دیتا
- تعریف، توصیف و بررسی ویژگی های کلیدی بیگ دیتا
- جایگاه بیگ دیتا و پردازش بیگ دیتا
- کاربرد بیگ دیتا و تحلیل آنها
- منابع تولید کننده بیگ دیتا
- چالش های مدل های سنتی ذخیره سازی در مواجهه با بیگ دیتا
- داده های Stream، مشخصات و تولید کننده های آن ها
- کاربرد و علت Stream Processing
-
معرفی Hadoop و شروع کار با اکو سیستم Hadoop
- معرفی Hadoop به عنوان سکوی پردازش و ذخیره سازی بیگ دیتا
- آشنایی با اجزا Hadoop
- مدل پردازش توزیع شده MapReduce
- سیستم فایل توزیع شده Hadoop HDFS
- سیستم مدیریت منابع و وظایف YARN
- قابلیت ها و توانمندی های Hadoop
- نقاط قوت و ضعف Hadoop در مقایسه با سیستم های پردازشی موجود
- معرفی مدل پردازشی MapReduce
- مراحل انجام کار در اجرای وظایف MapReduce
- حل مسئله شمارش کلمات در MapReduce
- معماری و ویژگی های HDFS
- نحوه عملکرد HDFS NameNode و DataNode و وظایف هر کدام
- ساختار داده ها و بلاک ها در HDFS
- معرفی YARN
- اجزاء YARN
-
بخش Apache Spark
- معرفی Spark و مدل پردازش در Spark
- ویژگی ها و کاربرد های Spark
- انواع روش های مدیریت منابع در Spark
- بررسی معماری Apache Spark Spark Session Spark Context
- آماده سازی محیط توسعه و نصب Spark
- Spark Core
- مدل داده ای
- Operations
- Transformations
- Actions
- تبدیل منابع داده ای به RDD
- Submit Jobs
- Jobs, Stages, and Tasks
- مانیتورینگ Job ها
- RDD Execution Plan
حاصل دوره
دانشجویان عزیز پس از گذراندن این دوره آموزشی علاوه بر شناخت کامل مفاهیم بیگ دیتا، درک کاملی از اکوسیستم هدوپ و موتور پردازشی توزیع شده آپاچی اسپارک پیدا می کنند و می توانند از ابزارهای مربوطه جهت انجام فعالیت های لازم در حوزه مهندسی، تحلیل و علم داده استفاده کنند.
دانلود دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت اول ویدئو
27:34
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت دوم ویدئو
5:06
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت سوم ویدئو
7:55
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت چهارم ویدئو
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت پنجم ویدئو
9:24
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت ششم ویدئو
8:07
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت هفتم ویدئو
10:08
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت هشتم ویدئو
15:11
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت نهم ویدئو
8:55
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت دهم ویدئو
12:04
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت یازدهم ویدئو
8:38
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت دوازدهم ویدئو
17:27
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت سیزدهم ویدئو
25:02
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت چهاردهم ویدئو
23:17
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت پانزدهم ویدئو
20:33
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت شانزدهم ویدئو
20:47
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت هفدهم ویدئو
15:43
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت هجدهم ویدئو
13:13
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت نوزدهم ویدئو
5:49
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیستم ویدئو
4:26
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و یکم ویدئو
7:27
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و دوم ویدئو
8:01
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و سوم ویدئو
7:29
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و چهارم ویدئو
16:13
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و پنجم ویدئو
10:22
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و ششم ویدئو
7:45
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و هفتم ویدئو
13:03
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و هشتم ویدئو
16:30
دوره آموزشی بیگ دیتا با هدوپ و آپاچی اسپارک، قسمت بیست و نهم ویدئو
8:25
دانلود قطعه کدهای دوره
دانلود قطعه کدها
مجاز برای افرادی که دوره را تهیه کرده اند
دوره های مرتبط

دوره آموزشی تحلیل شبکه های اجتماعی و پیچیده با پایتون

کارگاه آموزشی پروژه محور شباهت سنجی رنگ ها و تصاویر با پایتون

کارگاه آموزشی پروژه محور طراحی و پیاده سازی انباره داده با آپاچی اسپارک

دوره آموزشی پروژه محور تکنیک های داده افزایی در پردازش زبان طبیعی

دوره جامع پروژه محور یادگیری عمیق با پای تورچ (PyTorch)
Deep Learning with PyTorch Framework

دوره آموزشی پروژه محور تحلیل داده ها در پایتون

بصری سازی پیشرفته تصاویر پزشکی بر بستر Google Colab



امتیاز دانشجویان دوره
نظرات
تنها اشخاصی که این محصول را خریداری کرده اند و وارد سایت شده اند می توانند در مورد این محصول بازبینی ارسال کنند.
99,000 تومان
ثبت نام دوره متوقف شده است

محمد حیدری
علاقه مند به داده هامهندس کلان داده و هوش مصنوعی، سداد، پژوهشگر مهندسی داده، پژوهشگاه دانش های بنیادی، ارشد علوم داده، تربیت مدرس تهران
امین میرلوحی( دانشجوی دوره )
سلام در سال ۱۴۰۳ دارم این دوره رو دنبال میکنم و فوق العاده لذت میبرم. فقط چند تا نکته هست
لینک دانلود کدهای دوره از کار افتاده.
آموزشها کمی قدیمی شده. اگر قصد ندارید دوره رو آپدیت کنید لطفا لیستی از مباحثی که جدید هست یا تغییر کرده تهیه کنید تا بعد از دوره بررسی کنیم.
تشکر
محمد علی( دانشجوی دوره )
دوره خوبی بود ومطالب کاملی رو پوشش داده شده است.
مهدی( دانشجوی دوره )
برای اونایی که تازه میخوان با اسپارک آشنا بشن خوب بود
وحید شاکری( دانشجوی دوره )
با تشکر از دوره خوب و جامعی که تهیه کردید. تصمیم ندارید دوره جدید اسپارک رو آماده بفرمایید؟ واقعا نیاز هست و منتظریم. چون نسخه 3.0 نسبت به 2.4.7 تو بعضی متدها دچار تغییرات شده.