
پردازش زبان طبیعی با یادگیری عمیق
مقدمه
یکی از شاخههای مهم و اساس در هوشمصنوعی، پردازش زبانهای طبیعی میباشد. این شاخه در تلاش است تا به بررسی نحوه ارتباط انسانها با یکدیگر از طریق تکلم بپردازد. اینکار باعث افزایش تعامل انسان و ماشینهای هوشمند گردیده و بعنوان یک دستیار انسان را برای پردازش اسناد نوشتاری و گفتاری، یاری مینماید. گرچه انتقادهای زیادی به نحوه پیادهسازی و بکارگیری الگوریتمهای مربوط به این تکنولوژی وجود دارد، اما همچنان از روشهای عددی برای پیادهسازی آن بهره برده میشود. بعنوان نمونه نظریه اتاق چینی، برای اولین بار توسط فیسوف معروف آمریکایی به نام جان سرل مطرح گردید، که به انتقاد از روشهای پیادهسازی زبانهای طبیعی بشری در ماشینهای هوشمند پرداخته است. در مباحث بعدی میتوانید در مورد این نظریه بیشتر مطالعه کنید. در این بخش ما نیز به پژوهش و بررسی روشهای موجود خواهیم پرداخت. در این نوشته، هدف اصلی ما درک ماهیت پردازش زبانهای طبیعی توسط ماشینهای هوشمند است. بنابراین نهایت تلاشمان بر این است از محاسبات مربوط و روشهای پیچیده ریاضی دوری کنیم تا مطالعه آن روانتر و راحتتر باشد.
تاریخچه
در سال ۱۹۵۷ نوام چامسکی برای اولین بار در زمینه پردازش زبانهای طبیعی، کتابی با عنوان ساختار نحوی ارائه نمود. وی در آن کتاب بر این عقیده بود که کامپیوترها میتوانند زبان بشری را یاد بگیرند. برای اینکار نیز یک ساختار گرامری مخصوص سیستمی هم طراحی نمود. این ساختار میتوانست شکل اصلی زبانهای طبیعی که توسط بشر استفاده میگردید را به زبان کامپیوتر ترجمه نماید. هدف کلی این بود که سیستمها هم همچون انسان بتوانند از طریق زبانهای بشری با محیط اطراف خود بصورت هوشمند ارتباط برقرار نمایند. این تحقیقات تا سال ۱۹۶۶ توسط سایر دانشمندان نیز ادامه یافت. در همین راستا زبان برنامه نویسی لیسپ توسط جان مککارتی معرفی گردید. با این وجود، اواخر دهه شصت هزینه ترجمههای دستی زبانها توسط انسان به شدت کمتر از استفاده از سیستمهای کامپیوتری با تکنولوژی آن زمان بود. در نتیجه تحقیقات متوقف گردید.
این تحقیقات از سال ۱۹۸۸ با پیشرفت و ورود علوم آمار و احتمالات وارد فاز جدیدی شد. بگونهای که استفاده از دادههای آماری و الگوریتمهای محاسباتی به تحلیل و بررسی زبانهای طبیعی پرداخته شد. همچنین از سال ۲۰۰۱ یوشیو بنجیو و همکارانش توانستند مدل جدیدی از پردازش زبانهای طبیعی را ارائه نمودند. در مدل خود استفاده از شبکههای عصبی مد نظر قرار گرفت. شبکههای عصبی بازگشتی و همچنین LSTM نیز به میان آمدند. در سال ۲۰۱۱ شرکت اپل اولین دستیار هوشمند خود بنام سیری را رونمایی کرد. این دستیار هوشمند میتواند به راحتی صحبتهای انسان را درک کرده و به آن پاسخ مناسب ارائه نماید. در این شرایط الگوریتمهای یادگیری ماشین نیز پیشرفت چشمگیری داشتند. با این حال ماشینها توانایی شبیهسازی مغز انسان در درک کلمات و جملات را ندارند. در نتیجه آنها را تبدیل به اعداد و ارقام کرده و از احتمالات برای پردازش زبانهای طبیعی استفاده مینمایند.
در ادامه ابتدا به بررسی کاربرد پردازش زبانهای طبیعی خواهیم پرداخت و به این سؤال که چرا بدنبال آموزش زبانهای گفتاری بشر و ساختار آن به ماشین هستم. سپس نحوه پیادهسازی آنرا مطالعه خواهیم کرد. در نهایت مبحث را با معرفی ابتدایی الگوریتمهای موجود در پردازش زبانهای طبیعی به پایان میرسانیم.
کاربرد پردازش زبانهای طبیعی
پردازش زبانهای طبیعی کاربردهای فراوانی در زمینههای مختلف علمی و صنعتی دارد.
۱ . ترجمه :
تصور کنید که قصد دارید به سفر دور دنیا بروید و یا اینکه در شبکههای اجتماعی نظرات کاربران جوامع مختلف را جویا شوید. قطعاً استفاده از دیکشنری و جستوجو در میان هزاران زبان مختلف میتواند یک راهکار باشد اما راهکاری که ممکن است روزها یا هفتهها برای درک یک جمله وقت و انرژیتان تلف شود. همچنین قرارگیری کلمات ترجمه شده در کنار هم نیز ممکن است مفهوم درست را منتقل نکند. بجای اینکار میتوان به یک ماشین هوشمند زبانهای مختلف دنیا را آموزش داد تا به شما کمک کند در لحظه جملات خارجی را به زبان مادری شما ترجمه کند. همچون مترجم گوگل.

۲ . دسته بندی اسناد نوشتاری
اگر یک خبرنگار مطبوعاتی و یا ادمین یک شبکهی اجتماعی باشید، برای آسایش کاربرانتان باید به آنها قدرت انتخاب دهید تا به مطالعه موضوع مورد علاقهی خود بپردازند. در نتیجه بجای خواندن تک تک متون و اخبار و یا هر اثر نوشتاری، میتوانید آنها را در اختیار ماشین هوشمند خود قرار دهید تا بتواند در زمانی اندک موضوع اسناد را به دستههای علمی، اجتماعی، فرهنگی و … تقسیم نمایند. این باعث میشود کاربران شما به راحتی به سراغ موضوع مورد نظر خود بروند.

۳ . دسته بندی معنایی
شما و خانوادیتان به طور پیوسته در حال استفاده از فضای مجازی هستین. یکی از دغدغهتان این است که کسی با ارسال محتوای تهدیدآمیز و الفاظ رکیک، روح و ذهن خانوادهتان را آزار دهد. اما با گسترش تکنولوژی خصوصا در زمینه پردازش زبانهای طبیعی این نگرانی شما برطرف میگردد. اینگونه که شبکههای اجتماعی هوشمند به راحتی میتوانند محتویات فضای را پایش نموده و محتوای نامناسب را سریعاً از بین ببرند. همچون توییتر و فیسبوک که الفاظ رکیک و نژاد پرستانه را به سرعت شناسایی و حذف مینمایند.
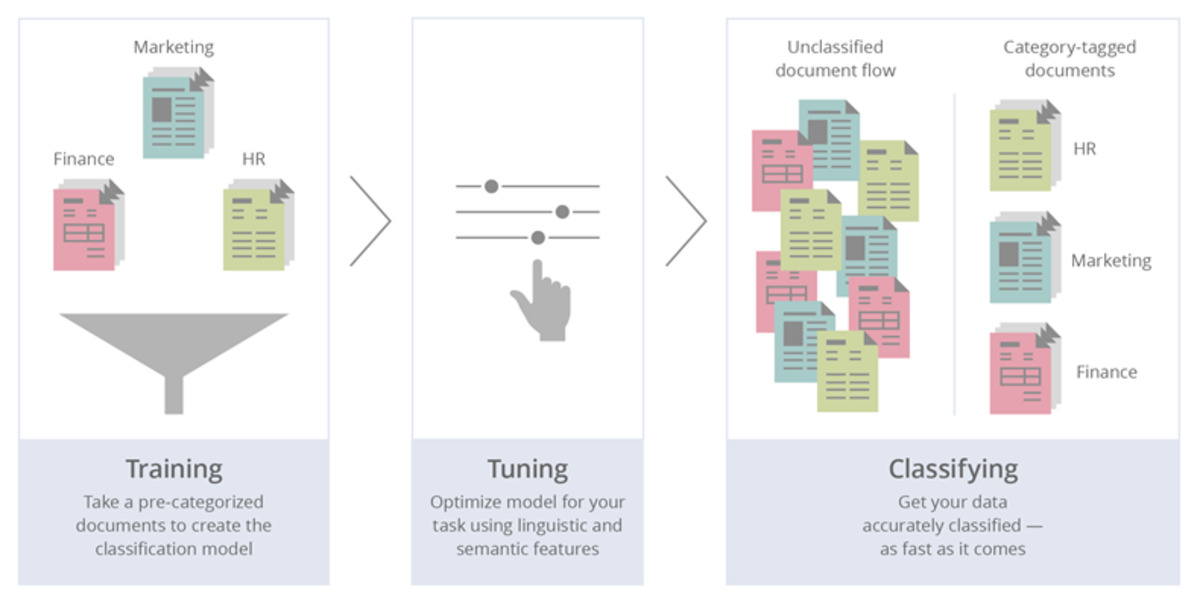
۴ . خلاصه سازی
در بعضی از مواقع به اسناد حجیمی در فضای مجازی بر میخورید که خارج از حوصله شما برای مطالعه آنها میباشد. از طرفی قصد دارید که از محتوای آنها با خبر شوید. میتوانید یک نفر را استخدام کنید تا برای شما خلاصهبرداری کند یا خودتان به ماشین هوشمند خود یاد دهید تا هر میزان اسناد را خلاصه نموده و رایگان در اختیارتان قرار دهد.
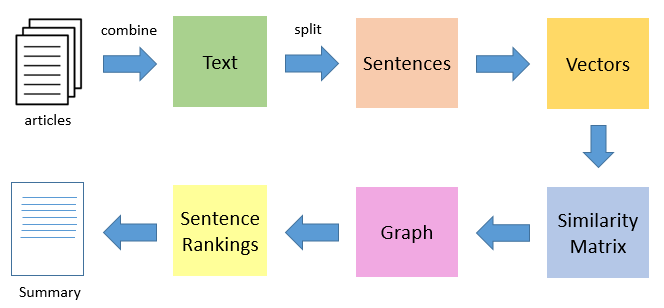
بررسی چالشهای مربوطه
همانطور که در بالا اشاره شد، هدف اصلی پردازش زبانهای طبیعی، ایجاد تعامل بین انسان و ماشینهای هوشمند میباشد. به گونهای که از جانب انسان در خواستی مطرح میگردد و ماشین به آن درخواست واکنش نشان میدهد. برای درک بهتر این فرایند معمولاً عمل پردازش را به دو بخش اساسی فهم زبانهای طبیعی و تولید زبان طبیعی، تقسیم مینمایند. بگونهای که ماشین ابتدا باید زبان بشر را درک نموده و سپس با تولید جملات از همان زبان پاسخگوی درخواستهای بشری باشد. بگونهای که انسان بتواند آنرا درک کند.
همیشه مرحله اول سختتر از مرحله دوم میباشد. شاید با خود بپرسید که چگونه؟! خب در زیر به بررسی هر دو مرحله خواهیم پرداخت و سپس در مورد سختی مراحل اظهار نظر میکنیم.
یک ماشین هوشمند برای اینکه بتواند زبان بشری را درک نماید دارای سه چالش مهم است:
۱. ابهام واژگانی
ابهام واژگانی به حالتی گفته میشود که یک واژه در توصیف مفهوم جمله ابهام ایجاد نماید. در این وضعیت حتی میتواند برای انسان نیز گنگ باشد! در زیر یک مثال از این نمونه آورده شده است:
He is Looking for a Match
در مثال بالا کلمه match دارای دو معنی جور شدن و یا یک مسابقه ورزشی دارد. پس جمله بالا دارای دو معنی خواهد داشت:
معنی اول : او بدنبال یک همدم است
معنی دوم: او بدنبال یک مسابقه ورزشی است.
یکی از راهکارهای ساده استفاده از روش تگ کردن اجزای جملات است که به آن خواهیم پرداخت.
۲. ابهام نحوی
در این چالش، ترتیب قرارگیری بین کلمات میتواند چندین مفهوم را به مخاطب منتقل نماید. در این وضعیت نمیتوان درست حدس زد که منظور نحوی جمله به چه وضعیتی اشاره دارد. بدین معنی که موقعیت دستور زبانی کلمات دارای ابهام هستن. همچون مثال زیر:
The chicken is ready to eat
در جملهي بالا مشخص نیست که کلمه chicken فاعل است یا مفعول. در هر حالت جمله دارای معنی و ساختار درست است.
۳. ابهام مرجع
در شرایطی که بیش از یک جمله وجود داشته باشد و یک جمله به کمک ضمایر اشاره به عناصر جملات دیگه اشاره میکند. اما در این حالت امکان دارد نتوان حدس زد که عناصر مورد اشاره ضمیر، کدام هستند. در مثال زیر ضمیر اشاره مشخص نیست که به دو نفر اشاره دارد یا تمامی افراد.
Mohammad met Ahmad and Mojtaba. They went to the Mosque
چالشهای بالا نشان دهنده سختی مرحله درک زبان طبیعی توسط ماشین بود. اما تولید محتوا توسط ماشین هوشمند به مراتب آسانتر میباشد. هر چند که باید یاد بگیرد که چگونه از ساختار درست جملات بهره ببرد. معانی کلمات را از طریق استخراج دانش دستور زبانی و بررسی ساختاری کلمات بدست آورد.
انواع تحلیلهای مربوطه
منابع زبانهای طبیعی هم میتواند گفتاری و همچنین نوشتاری باشد. اما مراحل پیادهسازی و اجرای الگوریتمهای مرتبط در بین این دو منبع یکسان میباشد. هر چند که در جزییات میتوانند متفاوت باشند.
۱. تحلیل ریختشناسی
در این مرحله ابتدا ساختار کلمات مورد بررسی قرار میگیرن. به گونهای که پسوندها و پیشوندهای موجود در ساختار کلمات شناسایی شده و از کلمه اصلی جدا میگردند. به گونهای که ریشه اصلی کلمه مورد نظر بدست آید. سپس ریشهیابی معنایی کلمات توسط ماشین هوشمند انجام میگردد.
۲. تحلیل لغوی
در این بخش وقتی که یک سند متنی به سیستم داده میشود، ماشین ابتدا آنرا به پارگرافهای جداگانه، جملات جداگانه و در نهایت کلمات جداگانهی موجود در جمله، تقسیم مینماید. هر کلمه را بررسی ریشهای مینماید.
۳. تحلیل نحوی
در جملات کلماتی هستند که به تنهایی معنی خاصی دارند. ولی با توجه به روابط دستور زبانی کلمات در جمله، معنی آن تغییر میکند. حتی ممکن است در جملات بدون استفاده گردند.
۴. تحلیل معنایی
جملات دارای معانی متفاوت میباشند. که منظور اصلی آنها از طریق تحلیل دستورزبانی و ساختاری مفهوم نهفته در جمله، توسط ماشین استخراج میشوند.
5. ادغام گفتاری
در جملات، کلماتی وجود دارند که معانی آنها براساس وابستگی که به کلمات پیش و پس از آن، وجود دارد تعیین میگردند.و به تنهایی مفهوم جمله را نمیرسانند.
۶ .تحلیل عملی
در یکسری از جملات ممکن است ضمایر اشاره دارای مفاهیم متفاوتی باشند. که میتوانند جزیی از ابهام مرجع که در چالشها مطرح شد نیز باشند. اما در این جملات، ماشینها نیازمند دانش بسیار زیادی در حوزه صرف و نحو کسب کرده باشند. بعنوان مثال به دو جمله زیر توجه نمایید.
– والدین به فرزندان اجازه بازی نمیدادند زیرا آنها از بازیگوشی حراص داشتن.
-والدین به فرزندان اجازه بازی نمیدادند زیرا آنها بازیگوش بودن.
در جمله اول ٬آنها٬ به والدین اشاره دارد و دومی به فرزندان. این تمایز در صورتی توسط ماشین شناسایی میشود که سطح دانش بالایی نسبت به محیط اطراف داشته باشد.
مراحل پردازش زبانهای طبیعی
تمامی مطالبی که تا الان مطرح گردید، مسائل مهمی هستند که ماشینهای هوشمند امروزی و طراحان ماشینها،با آنها مواجه هستن. شناخت چالشها و تحلیل دادهها در پردازش زبان های طبیعی استفاده از ابزارها و راهکارها را تسهیل مینمایند.
مراحل پیادهسازی پردازش زبانهای طبیعی و همچنین نحوه اجرای الگوریتمها از اهمیت بالایی برخوردار است. در زیر مراحل اجرای پردازش را بررسی مینماییم.
۱. جداسازی جملات
از آنجایی که یک سند نوشتاری از چندین پاراگراف تشکیل گردیده است، جملات موجود در پاراگرافها را از یکدیگر جدا مینماییم. در این حالت مجموعهای از جملات ساده و جدا از یکدیگر ایجاد میگردد.
۲. جداسازی کلمات
حال در این مرحله کلمات موجود در جملات را نیز جداسازی مینماییم. بگونهای که بجای هر جمله، مجموعهای از کلمات را در اختیار خواهیم داشت.
۳. اجزای گفتاری
در این مرحله نقش دستور زبانی کلمات موجود در مجموعه مرحله قبل را بدست میاوریم. باید به این موضوع توجه داشت که ماشین ابتدا تعداد بالایی از نمونههای لغوی و دستور زبانی زبان مورد نظر را به صورت آماری یاد گرفته و سپس میتواند جایگاه لغوی، کلمات در جمله را حدس بزند. در زیر یک مثال از این مرحله را میبینید. این مرحله یکی از راهکارهای ساده برای چالشهای مطرح شده در بالا میباشد.
4. ریشهیابی کلمات
در این روش سعی بر این است که پسوند و پیشوندهای مربوط به قواعد دستور زبانی کلمات حذف گردیده و تا کلمه، خالصسازی گردد. در مثال زیر دو روش برای انجام اینکار دیده میشود که stemming شناسایی و حذف پسوندها استفاده گردیده و Lemmatization نیزبرای شناسایی شکل ساده کلماتی که به ازای قواعد زمانی در جمله، تغییر یافتهاند.
۵ . شناسایی کلمات اضافه
در زبانهای طبیعی کلماتی وجود دارند که به تعداد زیادی تکرار میگردند. از آنجایی که بیشتر روشهای پردازشی در زبانهای طبیعی، آماری هستند، تعداد زیاد کلمات اضافی که میتواند شامل کلمات ربطی، ضمایر و … باشند، باعث ایجاد تغییرات ناخواسته در خروجی نتایج گردند. بنابراین یک مجموعهی کاملی از این لغات بصورت یک دیکشنری جمعاوری شدهاند که هرکدام مخصوص زبان خاصی هستند. که ماشین با یادگیری آنها میتواند به حذف حروف اضافی اقدام نماید. در مثال زیر لغات با رنگ طوسی حروف اضافی هستند که توسط ماشین شناسایی گردیده اند.

۶ . تجزیه روابط
در تمامی زبانهای طبیعی، یک جمله ساده، مفهوم خاصی را منتقل مینماید. در حالیکه برای ارائه جزییات بیشتر از کلمات وصفی، قیدی و … استفاده میگردد. یکی از مباحثی که ماشینها در هنگام یادگیری زبانهای انسانی با آنها مواجه هستند، درک درستی از هدف اصلی جمله و تشخیص صفات و قیدهایی که در جمله مطرح میشوند، میباشد. در اینجا ماشین باید بتواند همچون انسان تشخیص دهد که کلمهی توصیفی در جمله اشاره به کدام بخش از اجزای اصلی جمله دارند. همچون مثال زیر:
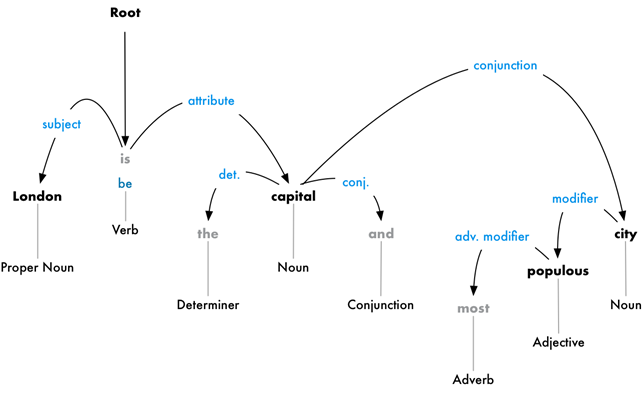
در مثال بالا هدف اصلی جمله معرفی شهر لندن بعنوان یک پایتخت است. حال آنکه برای توضیحات بیشتر، آنرا شلوغترین شهر کشور مربوطه مطرح مینماید. ماشین هوشمند باید بتواند این را تشخیص دهد که شلوغترین بودن مربوط به لندن به عنوان یک شهر میباشد. این در حالیست که نقش اجزای اصلی جمله باید حفظ شوند تا مفهوم اصلی آن تغییر نیابد.
۷. شناسایی نوع اجزا
در جملات یک ماشین هوشمند میتواند نوع کلمات موجود در جملات را شناسایی نمایند. کلمهای میتواند بعنوان یک سازمان شناسایی گردد. و یا نام یک کشور، شهر یا حتی مدل لباس باشد. همچون مثال زیر:

در مثال بالا کلمات لندن، انگلستان و بریتانیا موقعیت جغرافیایی میباشند.
تمامی مراحل بالا در شکل زیر بصورت ترتیبی و خلاصه آورده شده است.

مدلهای پردازش زبان طبیعی و پیادهسازی آنها
در پیادهسازی و پردازش زبان طبیعی ابتدا باید یک چهارچوبی را رعایت نمود. که این چهارچوب شامل پیش پردازش، مدلسازی و نتیجه حاصل میباشد. این مراحل در تصویر زیر آورده شده اند:
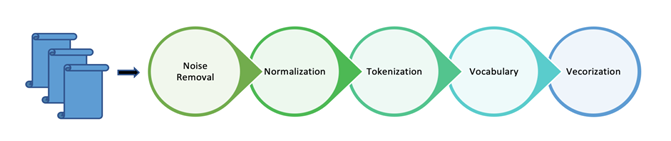
همانطور که در تصویر مشخص است، ابتدا باید نویزها از جمله کلمات اضافی، علایم نگارشی و همینطور در برخی موارد اعداد را از میان برداشت. سپس در بخش نرمال سازی ساختار لغوی کلمات را بررسی نموده تا پسوند و پیشوندهای مربوط به قواعد و همچنین تغییرات زمانی کلمات شناسایی و برطرف گردند. همچنین حروف بزرگ به حروف کوچک در برخی از زبانها تبدیل میگردند. در همین مرحله نرمالسازی باید اعدادی که به حروف نوشته شدهاند نیز به اعداد رقمی تبدیل گردند. جدا سازی کلمات و ایجاد یک دیکشنری از لغات بسیار میتواند سودمند باشند. در نهایت کلمات باید به زمان ماشین ترجمه گردند که همان بردارها و ماتریسهای عددی میباشند که در مدل سازی های بعدی بکار خواهند آمد. حال که با این مراحل پیش پردازش داده و آماده سازی آن برای مدل کردن، آشنا شدین به سراغ خود مدلهای مهمی که تا به امروز طراحی شده آن میرویم.
همانطور که در تاریخچه مطرح شد پردازش زبان طبیعی و درک آن توسط ماشین با چالشهای فراوانی روبرو گردیده است. این وضعیت منجر ارائه مدلهای مختلفی جهت بهبود عملکرد و کاهش هزینههای محاسباتی شده است. در حالت کلی همانطور که در شکل زیر مشاهده مینمایید، ۶ مدل اصلی از nlp ارائه گردیده. که البته به ۴ تای اول آن اشاره نموده. در نوشتههای بعدی به توضیح مفصل دو مرحله آخر خواهیم پرداخت که در این نوشته نمیگنجند.
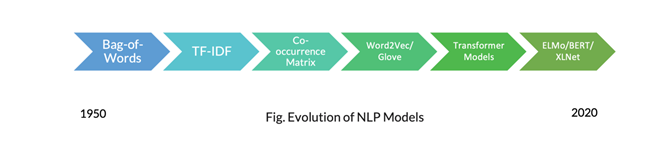
۱. مدل کولهپشتی کلمات
این مدل در سال ۱۹۵۰ معرفی گردید. بسیار ساده و در عین حال مناسب برای سیستمهای آن دوران. تنها کاری که این مدل انجام میدهد، شمارش تعداد رخداد هر کلمه در یک متن میباشد. که البته همانطور که در مورد حروف اضافه در بالا صحبت شد، با تعداد بالایی که دارن میتوانند هزینه محاسباتی سیستم را بالا ببرند. در کل منطق این مدل بر این اساس است که تعداد کلمات یک متن را شمارش کرده و موضوع متن و اهداف آنرا از طریق بررسی کلمات با بیشترین تکرار بدست میآورد.
۲. مدل فراوانی وزنی(TF-IDF)
مدل کوله پشتی کلمات بعنوان یک مدل اولیه، یک شروع امیدوار کننده بود. اما نقص بزرگی در آن بود. اینکه به صورت حریصانه تکرار کلمات متن را بدست آورده و رده بندی مینمود. این در حالی بود که بعضی از کلماتی در جملات بودن که در عین تکرار بالای آنها، هیچ ربطی به موضوع اصلی متن نداشتن-همچون حروف ربطی. در نتیجه تصمیم بر این شد تا روشی محاسباتی تر ارائه گردد. بدین منظور مکانیزمی را طراحی نمودند تا ماشین، کلمات اضافی و نامربوط را کنار گذاشته و تنها به شمارش تعداد تکرار کلمات مربوط به متن بپردازد. پس دو متغیر فراوانی کلمات مربوطه و فراوانی متن در نظر گرفته شد. تنها به منظور درک بهتر، فرمول محاسباتی آن در زیر آمده است.

۳. ماتریس همزمانی
روش فراوانی وزنی تا حدود زیادی مشکلات محاسباتی را با حذف حروف اضافی، برطرف نمود. مشکل مهمتری همچنان پا برجا بود که آن چیزی نبود جز عدم شناسایی روابط معنایی بین کلمات. چیزی که میتونست براحتی منجر به یک فاجعه گردد. همانطور که در بخش ابهامات مطرح کردیم دقیقاً باید ارتباط بین لغات به ماشین یاد داده شود تا بتواند تحلیل معنایی بهتری از جمله بدست آورد. در زیر نمونهای از ماتریس همزمانی را مشاهده میفرمایید.
۴. مدل word2vec
این روش تفاوتهای فنی بسیاری با روشهای قبلی دارد. زیرا از روشهای یادگیری ماشین و شبکههای عصبی استفاده گردیده است. به این صورت که لغات موجود در یک متن را به برداری از اعداد تبدیل مینماید. که البته مغز انسان در بخش گفتاری اینگونه عمل نمیکند! دلیل انتقادهایی که در بالا به آنها اشاره کردیم هم همین بود. در هر صورت این مدل دارای زیر مجموعههایی هستند که تنها به یکی از پرکاربردترین آنها به نام skip-gram میپردازیم. این روش بمنظور کد کردن کلمه موجود در متن ، ابتدا ارتباط آن با کلمات همسایهی در آن متن را بررسی مینماید. برای انجام اینکار نیز یک پنجره با اندازهای خاص را تعیین میکند برای درک بهتر تصویر زیر بسیار مفید خواهد بود.
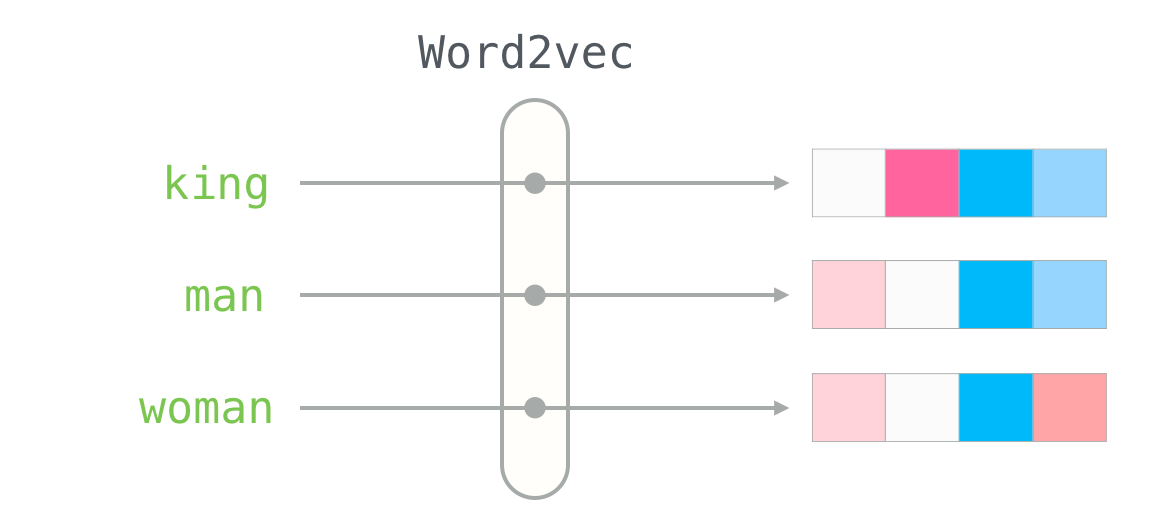
در این بخش، جفت نمونههایی بدست میایند که میتوانند کلمه هدف را پیشبینی نمایند. در نتیجه بمنظور تبدیل حروف به برداری از اعداد، فاصله برداری جفت هایی که بیشتر رخ میدهند به هم نزدیکتر خواهند بود و بدین شکل ماشین یاد میگیرد که ارتباط بین آن کلمه با سایر کلمات را درک نماید. پس از آن، به کمک یادگیری عمقی و ابزارهای مربوط به آن میتوان از بردارهای بدست آمده بهره برد.
نتیجه گیری
در توضیحات بالا سعی بر این شد تا چالشها و انگیزههای استفاده از پردازش زبانهای طبیعی در هوش مصنوعی مطرح شد. پیادهسازی و نحوه طراحی الگوریتمهای مربوط به این شاخه و از همه مهمتر نحوهی درک آنها ارائه گردید. در نهایت تمامی اینها فارغ از کاراییهای متفاوتی که دارد، به یک چیز ختم میشود آن هم طراحی رباتهای گفت گو (چت بات) و آموزش آنها بمنظور ارتباط با بشر میباشد.
مطالب زیر را حتما مطالعه کنید

MLOps چیست؟

هوش مصنوعی مولد یا Generative AI چیست؟

چت بات هوش مصنوعی محور ChatGPT که در آینده جایگزین انسان خواهد شد

آشنایی با Graph Attention Network (شبکه های توجه گرافی)

طراحی شبکه های عصبی گرافی با استفاده از کتابخانه PyG در پایتون

متاورس و هوش مصنوعی
دوره های آموزشی مرتبط




دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.